这是关于什么的?
自动提示工程 (APE) 是一种自动生成和优化大型语言模型 (LLM) 提示的技术,旨在提高模型在特定任务上的性能。它采用了提示工程的理念,即手动制作和测试各种提示,并自动执行整个过程。我们将看到,它与传统监督机器学习中的自动超参数优化非常相似。
在本教程中,我们将深入研究 APE:我们将首先了解其工作原理、可用于生成提示的一些策略以及其他相关技术(例如样本选择)。然后,我们将进入实践部分,从头开始编写 APE 程序,即我们不会使用任何像 DSPy 这样的库来为我们完成这项工作。通过这样做,我们将更好地了解 APE 的工作原理,并更好地利用提供此功能的框架。
与往常一样,本教程的代码可在Github上获取(根据CC BY-NC-SA 4.0 许可)。
为什么它很重要?
在与组织合作时,我发现他们经常很难找到针对特定任务的 LLM 最佳提示。他们依靠手动制定和完善提示并对其进行评估。这非常耗时,并且通常会阻碍 LLM 的实际使用和生产。
有时感觉就像炼金术一样,因为我们在尝试不同的提示,尝试不同的结构和说明元素,希望找到最终能达到预期效果的提示。与此同时,我们实际上甚至不知道什么有效,什么无效。

这只是针对一个提示、一个 LLM 和一个任务而言的。想象一下,在有多个 LLM 和数百个任务的企业环境中必须这样做。手动提示工程很快就会成为瓶颈。它很慢,甚至可能更糟,限制了我们探索 LLM 提供的所有可能性的能力。我们还倾向于陷入可预测的思维模式,这会限制我们提示的创造力和有效性。
例如,我总是倾向于在 LLM 提示中使用相同的老技巧,例如思路链和少量提示。这没有什么错——通常,它们会带来更好的结果。但我总是想知道我是否从模型中“榨干了最多的精华”。另一方面,LLM 可以探索更广泛的提示设计空间,通常会想出意想不到的方法,从而带来显着的性能提升。
举一个具体的例子:在论文《古怪的自动提示的不合理有效性》中,作者发现以下提示对 Llama-70B 模型非常有效:
指挥部,我们需要您规划穿越湍流的路线并找到异常源头。利用所有可用数据和您的专业知识指导我们度过这一艰难时刻。
船长日志,星历 [在此处插入日期]:我们成功地穿越了湍流,并正在接近异常源头。
我的意思是,谁会想出这样的提示?但在过去几周尝试 APE 时,我一次又一次地看到,LLM 在提出此类提示时非常有创意,我们也将在本教程的后面部分看到这一点。APE 使我们能够自动化提示优化过程,并挖掘 LLM 应用程序的未开发潜力!
自动提示工程的原理
及时工程
经过大量实验后,各组织现在正考虑在生产中使用 LLM 执行各种任务,例如情绪分析、文本摘要、翻译、数据提取和代码生成等。其中许多任务都有明确定义的指标,并且可以立即评估模型性能。
以代码生成为例:我们可以通过在编译器或解释器中运行代码来检查语法错误和功能,从而立即评估生成的代码的准确性。通过测量成功编译的代码百分比以及代码是否真正执行了我们想要的操作等指标,可以快速确定 LLM 在该任务上的表现。
在指标定义明确的给定任务上,提高模型性能的最佳方法之一是提示工程。简而言之,提示工程是设计和改进 LLM 的输入提示以得出最准确、最相关和最有用的响应的过程。换句话说:提示是可以调整和改进以提高模型性能的超参数之一(其他超参数包括温度、top K等)。
然而,事实证明,手动提示设计非常耗时,需要很好地理解提示结构和模型行为。某些任务也很难准确而简洁地传达指令。而且它本质上不是最优的,因为作为人类,我们没有时间尝试每一个可能的提示及其变化。

这有点像监督机器学习 (ML) 的旧时代中的超参数优化(HPO):手动尝试不同的学习率、时期数、批次大小等不是最优的,也不实用。就像当时自动化 HPO 的兴起一样,我认为,手动快速工程的挑战将导致自动快速工程 (APE)的兴起。
APE 背后的核心思想
在监督式 ML 的自动化 HPO 中,可以使用各种策略系统地探索超参数值的不同组合。随机搜索非常简单直接,只需从定义的搜索空间中抽取固定数量的超参数组合即可。考虑到这一点,一种更先进的技术是贝叶斯搜索,它建立了目标函数的概率模型,以智能地选择最有希望的超参数组合进行评估。
我们可以将相同的原则应用于 APE,但我们首先需要解决的事实是,提示是一种不同类型的超参数,因为它是基于文本的。相比之下,传统的 ML 超参数是数字的,因此可以直接以编程方式为它们选择值。但是,自动生成文本提示要困难得多。但是,如果我们有一个永不疲倦的工具,能够生成无数各种风格的提示,同时不断改进它们,那会怎样?我们需要一个精通语言理解和生成的工具……那会是什么呢?没错,它将是一个 LLM!
事情还不止于此:为了以编程方式评估 LLM 的响应,我们经常需要提取模型响应的本质并将其与基本事实进行比较。有时可以使用正则表达式来完成,但通常这并不容易——模型的响应可以以某种方式制定,以至于正则表达式很难提取实际答案。假设 LLM 需要评估推文的情绪。它可能会分析推文并做出回应
“这条推文的整体情绪是负面的。用户表达了对音乐会体验的不满,并提到他们没有获得积极的体验,因为音乐声太大,他们听不到歌手的声音。”
通过正则表达式提取此分析的本质将非常困难,尤其是因为响应中同时包含两个词(positive和negative)。如果您认为 LLM 擅长快速将这种情绪分析与基本事实(通常只是negative这个词)进行比较,那么您是对的。因此,我们将使用另一个 LLM 来评估模型的响应并计算指标。
之所以有效,是因为我们用 LLM 来完成不同的任务。与 LLM 撰写论文,然后由同一个 LLM 审查和评论该论文的情况不同,我们使用 LLM 来完成彼此独立且完全在其能力范围内的任务。
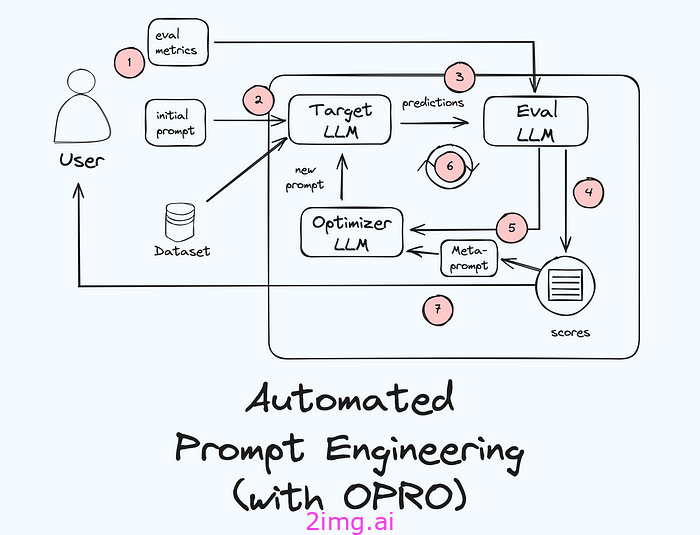
APE 工作流程
将我们迄今为止讨论的所有内容综合起来,我们得出了以下 APE 运行的工作流程:

让我们讨论一下这里发生的事情:
- 要开始使用 APE,我们需要准备以下要素:(1) 一个标记数据集,代表我们要为其创建优化提示的任务,(2) 一个初始提示,以及 (3) 一个我们可以进行爬山测试的评估指标。这再次与监督式 ML 中的 HPO 非常相似,我们将在其中提供训练数据集、超参数的初始起始值以及评估指标。
- 从初始提示开始:我们通过将初始提示和数据集发送到目标 LLM 来启动 APE 工作流程,这是我们想要在生产中使用并想要为其创建优化提示的 LLM。
- 生成响应: LLM 将根据数据集和初始提示生成响应。例如,如果我们有 10 条推文,初始提示是“识别此推文中的情绪”,则目标 LLM 将创建 10 个响应,每条推文一个情绪分类。
- 评估响应:因为我们的数据集已贴上标签,所以我们有每条推文的基本事实。评估器 LLM 现在将基本事实与目标 LLM 的输出进行比较,并确定目标 LLM 的性能并存储结果。
- 优化提示:现在优化器 LLM 将提出一个新的提示。我们将在下面讨论它的具体操作方式。但正如已经讨论过的,这类似于如何选择超参数的新值,并且它们有不同的策略。
- 重复步骤 3-5:生成答案、评估答案和优化提示的过程会反复进行。每次迭代,提示都会得到改进,从而(希望)获得越来越好的 LLM 答案。
- 选择最佳提示:经过一定次数的迭代或达到令人满意的性能水平后,我们可以停止工作流程。此时,性能最佳的提示(以及所有提示的分数)将发送回用户。
这种自动化过程使得 APE 能够在短时间内尝试大量不同的提示,速度比人类快得多。
快速优化策略
现在,让我们深入研究即时优化的策略,从最简单的开始:随机即时优化。尽管简单,但这种策略可以产生令人惊讶的有效结果。
随机提示优化
与随机搜索的 HPO 一样,随机提示优化采用“蛮力”方法。通过这种策略,我们让优化器 LLM 生成一系列随机提示,独立于之前的提示和结果。系统不会尝试从之前的结果中学习;相反,它只是随机探索各种潜在提示。
通过 PROmpting 进行优化 (OPRO)
如果随机提示优化类似于 HPO 中的随机搜索,那么 OPRO 类似于贝叶斯搜索。Google Deepmind 在本篇论文中介绍了这一策略。在 OPRO 中,我们利用之前迭代的结果,并积极尝试针对评估指标进行爬山。OPRO 会跟踪所有之前提示的分数,并根据它们在优化轨迹中的表现对这些提示历史进行排序,这成为一个宝贵的信息来源,可引导优化器 LLM 找到更有效的提示。如果这听起来有点抽象,请不要担心——一旦我们从头开始实施这一策略,它就会很快变得清晰。
OPRO 的关键是元提示,它用于指导优化者 LLM。这个元提示不仅包括通常的任务描述和示例,还包括优化轨迹。通过这个提示,优化者 LLM 可以分析优化轨迹中的模式,识别成功提示的要素并避免不成功提示的陷阱。这个学习过程允许优化者随着时间的推移生成越来越有效的提示,从而迭代地提高目标 LLM 的性能。
我们已经回顾了从头开始实施我们自己的 APE 工作流程所需的所有理论概念。但在此之前,我想快速介绍两件事:(1) 介绍小样本提示及其在 APE 中的位置和 (2) 现有的 APE 框架。
超越即时优化:样本选择的一瞥
虽然提示优化在 APE 中起着至关重要的作用,但它并不是我们工具箱中唯一的工具。在深入研究另一种强大的技术之前,让我们先快速讨论一下少样本提示。您可能已经知道,LLM 有时需要一些正确的指导。我们可以为他们提供一些所需输出的示例,而不是仅仅向他们提供说明并希望他们获得最好的结果。这称为少样本提示,它可以显著增强 LLM 对手头任务的理解和表现。
可以通过样本选择将小样本提示添加到 APE ,旨在为给定任务找到最佳的小样本示例,从而进一步提高优化提示的有效性。想法是,一旦我们通过 OPRO 找到了表现良好的优化提示,我们就可以使用一些示例来尝试进一步提高目标 LLM 的性能。这就是样本选择的用武之地:它系统地测试不同的示例集并跟踪它们的性能。就像提示优化一样,它会自动确定给定任务和给定(优化)提示的最佳小样本示例。
这是 APE 领域中另一个具有巨大潜力的研究领域,但就本篇博文而言,我们将只关注即时优化。我将把探索样本选择留作一项练习,供您改进即时优化。
现有的 APE 框架
您可能还会想:“如果 APE 如此强大,那么是否有工具/库/框架可以为我做到这一点?”答案当然是肯定的!像DSPy这样的库提供了现成的解决方案来实现快速优化(和样本选择)技术。这些库在幕后处理复杂的算法,因此您可以专注于使用 APE,而不必陷入技术细节中。
但是,虽然这些库无疑很有用,但它们通常像黑匣子一样运行,隐藏了优化过程的内部工作原理。然而,这篇博文和教程的目的是让我们了解幕后发生了什么。为此,我们将亲自动手编写一些代码,我们现在就开始吧!🧑💻
从头开始实现 APE
这个烦人的理论就到此为止了——让我们开始动手吧!在本节中,我们将使用Python、Vertex AI和Gemini 1.5 模型从头开始实现 OPRO 算法。我们将逐步分解该过程,并在此过程中提供清晰的解释和代码片段。最后,我们将拥有一个有效的 OPRO 实现,我们可以使用它来优化我们自己的 LLM 项目。
数据集
当我们谈论 APE 工作流程时,我们说我们需要提供一个数据集,我们可以用它来“训练”优化器 LLM。为了看到性能的提升,我们需要使用 LLM 难以正确处理的数据集/任务。
进入几何形状的世界——LLM 经常遇到困难的领域。空间推理和抽象视觉描述的解释对于这些模型来说并不是自然而然的事情,而且它们经常无法完成人类认为相当容易的任务。对于我们的实现,我们选择了Big-Bench Hard (BBH) 基准测试(在MIT 许可下开放)中的geometry_shapes数据集:给定一个包含多个命令的完整 SVG 路径元素,LLM 必须确定如果执行完整路径元素将生成的几何形状。以下是示例:

准备数据:训练集和测试集
在典型的数据科学项目中,我们将数据分成两组:一组用于训练模型(或在本例中优化提示),一组用于评估模型在未知数据上的表现的测试集。这种分离确保我们不会过度拟合训练数据,并且我们的模型可以推广到新示例。
对于我们的 OPRO 实现,我们将遵循相同的原则。我们将从几何形状数据集中随机选择 100 个示例作为我们的训练集,再选择 100 个示例作为我们的测试集。以下代码演示了如何使用 Hugging Face 数据集库执行此操作:
从数据集导入load_dataset
导入pandas作为pd
数据集 = load_dataset( “lukaemon/bbh” , “geometric_shapes” , cache_dir= “./bbh_nshapes_cache” )
数据 = 数据集[ “测试” ]
数据 = data.shuffle(种子= 1234 )
训练 = data.select(范围( 100 ))
df_train = pd.DataFrame({ “问题” : 训练[ “输入” ], “答案” : 训练[ “目标” ]})
测试 = data.select(范围( 100 , 200 ))
df_test = pd.DataFrame({ “问题” : 测试[ “输入” ], “答案” : 测试[ “目标” ]})
df_train.to_csv( “train.csv” , index= False )
df_test.to_csv( “测试.csv”,索引= False)
此代码加载几何形状数据集,随机打乱它(使用固定种子以确保可重复性),选择前 100 个示例进行训练,选择接下来的 100 个示例进行测试,并将它们保存为 CSV 文件。数据准备就绪后,我们便可以进行下一步:创建基线。
创建基线
在我们探讨是否能够以及在多大程度上提高 APE 性能之前,我们需要建立一个基线来衡量其影响。
我们首先评估目标 LLM 在训练数据上的表现——我们将使用这些数据来指导快速优化过程。这将为我们提供一个比较基准,并强调快速优化的必要性。以下是使用 Vertex AI 和 Gemini 1.5-flash 模型运行此基线评估的 Python 代码:
导入asyncio
导入pandas作为pd
从prompt_evaluator导入PromptEvaluator
从vertexai.generative_models导入HarmBlockThreshold、HarmCategory
如果__name__ == "__main__" :
df_train = pd.read_csv( 'test.csv' ) # 加载训练数据
target_model_name = "gemini-1.5-flash"
target_model_config = {
"temperature" : 0 , "max_output_tokens" : 1000
}
review_model_name = "gemini-1.5-flash"
review_model_config = {
"temperature" : 0 , "max_output_tokens" : 10
}
safety_settings = {
HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE,
}
review_prompt_template_path = 'review_prompt_template.txt' # 审查提示文本文件的路径
evaluator = PromptEvaluator(
df_train, target_model_name, target_model_config, review_model_name, review_model_config, safety_settings, review_prompt_template_path
)
prompt = input ( "请输入评估提示: " )
asyncio.run(evaluator.main(prompt))
此代码加载我们的训练数据,并允许我们输入将用于生成响应的初始提示。然后,PromptEvaluator类评估这些模型响应,该类使用此提示计算模型的准确性。以下是提示评估器的具体工作原理:
- 响应生成: prompt_evaluator 接受我们的提示并将其与目标 LLM(在我们的例子中是gemini-1.5-flash)以及来自数据集的问题一起使用来为每个问题生成响应。
- 与基本事实的比较:提示评估器将每个模型答案与相应的基本事实进行比较。
- 准确度计算: prompt_evaluator 计算有多少个响应与基本事实相符,并计算准确度。
以下是此类评估的一个示例:

在这种情况下,目标模型的响应包含正确答案(E),评估模型将该响应与基本事实进行比较并返回true,表明目标 LLM 正确解决了任务。
建立基线
现在让我们继续为非常基本的提示创建一个基线:
“解决有关几何形状的给定问题。”

我们可以看到,性能并不好,准确率只有 36%,应该还有很大的改进空间。不过,在使用 APE 之前,让我们尝试另一种提示,使用一种已被证明对 LLM 非常有效的技术,尽管对原始提示只有很小的改动:思路链 (CoT) 推理。CoT 提示指导 LLM 将复杂问题分解为更小的步骤,从而实现更合乎逻辑和准确的推理。
我们的 CoT 提示将是:
“解决给定的几何形状问题。一步一步思考。 ”

有趣的是:训练数据的准确率跃升至 52%,这表明即使是像“逐步思考”这样的简单附加功能也可以显著提高 LLM 的性能。让我们将这个改进的提示用作 APE 工作流程的基线和起点。
实施 OPRO 优化器
因此,我们已经实现了基线的评估机制,现在我们几乎准备好实现优化器,这是完成 APE 工作流程中缺失的一块拼图。让我们一步一步来做(双关语😉):
1. 设置阶段:模型和配置
我们已经看到我们使用 Gemini 1.5 Flash 作为目标模型。这意味着,在这个过程结束时,我们希望使用优化的提示将 1.5 Flash 部署到生产中。以下是完整列表:
- 目标法学硕士:这是我们尝试针对几何形状任务进行优化的法学硕士。我们将使用gemini-1.5-flash,因为它速度快且经济高效,非常适合速度和效率至关重要的实际应用。我们使用零度温度,因为我们希望尽可能减少这项任务的创造力(以及可能的幻觉)。
- 优化器 LLM:此 LLM 负责生成和优化提示,这是一项需要创造力和细微差别的任务。我们将使用功能更强大的gemini-1.5-pro来确保我们获得高质量和多样化的提示建议。我们还希望这个模型具有相当的创造力,这就是我们使用温度 0.7 的原因。
- Eval LLM:事实证明,将自由形式的答案与基本事实进行比较对于 LLM 来说是一项相当简单的任务。因此,我们可以再次使用成本高效的 1.5 Flash 来完成这项任务,温度为零。
2. 精心设计元提示
如前所述,元提示是指导优化者 LLM 如何生成有效提示的指导机制。它就像一个配方,结合了 (1) 优化目标、(2) 任务示例和 (3) 以前提示的历史及其表现 — 优化轨迹。
以下是我们将要使用的元提示模板的骨架:
<解释>我有一些提示及其相应的准确度。提示根据其准确度按升序排列,准确度越高,质量越好。</解释>
<PROMPTS>{prompt_scores}</PROMPTS>
每个提示都与围绕几何形状的问题陈述一起使用。
<示例><问题>此 SVG 路径元素 <path d=”…”/> 绘制一个 (A) 圆形 (B) 七边形 (C) 六边形 (D) 风筝形 (E) 线形 (F) 八边形 (G) 五边形 (H) 矩形 (I) 扇形 (J) 三角形 </问题> <答案> (B) </答案> </示例>
<TASK>编写一个新提示,该提示将达到尽可能高的准确度,并且与旧提示不同。</TASK>
<规则>…</规则>
注意{prompt_scores}占位符。这是运行时插入优化轨迹的地方。提醒一下:我们将按准确度升序对这些提示-准确度对进行排序,这意味着最不有效的提示将首先出现,而最有效的提示将排在最后。这有助于优化器 LLM 识别提示性能的模式和趋势,了解哪些提示较少,哪些提示更成功。
3. OPRO 循环:生成、评估、优化
现在我们已经做好了一切准备,我们可以让 APE 算法生成固定数量的提示,对其进行评估,并根据元提示和其中的优化轨迹对提示进行改进。
注意:为了加快此过程,我们将利用异步编程的强大功能。这使我们能够同时向 Gemini API 发送多个请求并并行处理响应,而不是等待每个请求逐一完成。
要使用 Gemini API 进行异步编程,您需要确保在 Vertex AI 项目设置中设置了适当的每分钟查询数 (QPM) 限制。更高的 QPM 限制允许更多的并行请求,从而进一步加快评估过程。或者,我们可以减少数据集中的记录数。
循环的主要逻辑如下(详细信息可以参见GH repo中的代码):
for i in range (self.num_prompts + 1 ):
if i == 0 :
new_prompt = self.starting_prompt
else :
metaprompt = self.update_metaprompt(self.prompt_history, self.metaprompt_template_path)
# 查找新的建议提示
match = re.search( r'\[\[(.*?)\]\]' , response.text, re.DOTALL)
if match :
new_prompt = match .group( 1 )
else :
await aioconsole.aprint( "No new prompt found" )
continue
# 为提示创建子文件夹
prompt_folder = self.create_prompt_subfolder(i)
# 将提示保存在子文件夹内的文本文件中
prompt_file_path = os.path.join(prompt_folder, 'prompt.txt' )
with open (prompt_file_path, 'w' ) as f:
f.write(new_prompt)
# 使用 PromptEvaluator 评估新的提示
accuracy = await self.prompt_evaluator.evaluate_prompt(new_prompt)
if i == 0 :
best_accuracy = Starting_accuracy = accuracy
# 存储结果
prompt_accuracies.append((new_prompt, accuracy))
# 如果当前准确度更高,则更新最佳提示
if accuracy > best_accuracy:
best_accuracy = accuracy
best_prompt = new_prompt
旁注:一窥优化者的“思维过程”
在运行此工作流程时,我发现非常有趣的是检查优化器在尝试提出新提示时的“思考过程”。正如元提示中的指示,它会分析先前的结果并识别模式:

然后,它根据该分析提出了一个新的提示。新提示周围的双方括号充当清晰的分隔符,使我们的代码可以轻松地从优化器的输出中识别和提取新提示。
4. 整理结果
为了便于分析 APE 运行的结果,我们的代码将为每次运行创建一个专用文件夹,并按时间戳进行组织。在此文件夹中,我们将为每个生成的提示创建一个子文件夹,名为 prompt_1、prompt_2 等。让我们来看看其中一个提示文件夹:
- prompt.txt:此文件包含提示本身的纯文本。我们可以轻松打开此文件来查看提示的确切措辞。
- evaluation_results.csv:此 CSV 文件保存了提示的详细评估结果。我们发现以下几列:
–问题:来自训练数据的原始问题。-答案:问题的正确答案。- model_response:目标 LLM 在给出此提示时生成的响应。- is_correct :
一个布尔值,表示 LLM 的响应是否正确。

通过检查每个提示的文件,我们可以深入了解不同提示如何影响 LLM 的表现。我们可以分析 LLM 答对或答错的具体问题,识别成功提示中的模式,并跟踪提示质量随时间的变化。
除了这些提示特定的文件夹之外,主运行文件夹还将包含最终结果:
- prompt_history.txt:按生成顺序列出提示的文件,提供优化过程的时间顺序视图。
- prompt_history_chronological.txt:一个列出提示的文件,按其在训练数据的准确性排序,让您可以看到提示质量的进展。

5. 选择并测试表现最佳的提示
完成 OPRO 循环的所有迭代后,我们将获得一系列提示及其相关准确度,整齐地存储在运行文件夹中。运行结束时,程序将输出性能最佳的提示、其准确度以及相对于起始提示的改进。

哇,81%,这真是一个相当大的进步!而且在我看来,新的提示也相当有创意:它想出了计算 SVG 路径中有多少个“L”命令的想法,并以此作为已绘制形状的指标!
我们现在可以使用这个提示并将其纳入您的 LLM 工作流程。但在此之前,我们应该再运行一个测试:在未见过的测试数据上测试这个提示。这将告诉我们提示的有效性是否超出了训练数据的范围。
首先我们需要在测试数据上建立一个基线(我们上面建立的基线是针对训练数据的):

使用 CoT 提示,我们在测试数据上实现了 54% 的准确率。这将作为我们评估 APE 运行效果的基准。
现在让我们在这个测试数据集上运行优化的提示:

我们达到了 85%!与我们的 CoT 提示相比,这是一个惊人的 31 个百分点的进步 😃
结论
恭喜!我们成功地为geometry_shapes数据集发现了一个新的、性能更好的提示。这证明了 APE 的强大功能和 OPRO 算法的有效性。
正如我们现在所看到的,设计有效的提示可以显著影响 LLM 的表现,但手动调整和试验的过程可能非常耗时,而且难以扩展。这就是为什么在我看来,APE 开始成为游戏规则的改变者,使我们能够利用自动化的力量来优化提示并释放 LLM 的全部潜力。
在这篇博文中,我们探讨了 APE 的核心思想,重点介绍了 OPRO 策略——提示优化的“贝叶斯搜索”。我们已经看到 OPRO 如何使用包含优化轨迹的元提示,让优化器 LLM 从过去的成功和失败中学习,并迭代地完善其提示生成策略。
但我们并没有止步于理论——我们还通过使用 Vertex AI 和 Google 的 Gemini 1.5 模型从头开始实施 APE 工作流程,从而实现了实际操作。通过自行构建,我们对流程有了更深入的了解,现在完全有能力在将 LLM 工作负载部署到生产中时使用 APE。我们的实施成功发现了一个新的提示,将具有挑战性的geometry_shapes任务的准确率从基线的 49% 提高到了前所未有的测试数据集上令人印象深刻的 85%。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5873