llama.cpp中的lookahead示例位于examples/lookahead目录下,主要是一个C++程序(lookahead.cpp),用于演示和实现lookahead decoding(前瞻解码)技术。这种技术是一种优化LLM(大型语言模型)推理的推测解码方法,旨在打破传统自回归解码的顺序依赖性,从而加速token生成过程,而无需额外的draft模型(如speculative decoding所需)。
相关论文地址:https://arxiv.org/abs/2402.02057
lookahead decoding技术的背景
lookahead decoding由hao-ai-lab提出(参考其GitHub仓库LookaheadDecoding),
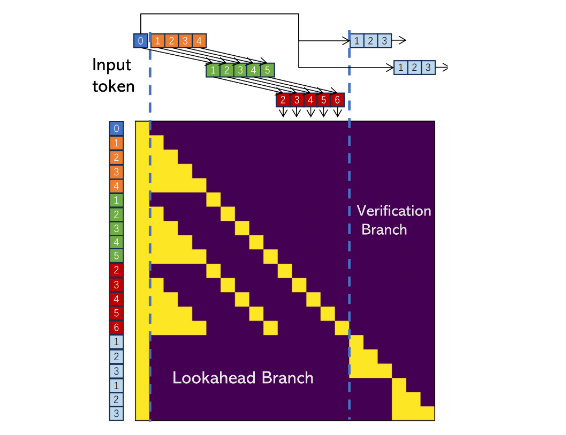
是一种并行解码策略。它通过在前瞻窗口中预测多个可能的token序列,并利用树状结构(如trie)验证这些序列,从而在单次前向传播中处理更多token。相比传统逐token解码,它可以实现1.5~2x的加速,尤其适用于LLaMA系列模型。 核心优势包括:
- 无需额外模型:不像speculative decoding需要小型draft模型,它直接在主模型上运行。
- 并行处理:通过大batch解码(large batches)来实现加速,但这要求硬件有足够的FLOPS(浮点运算能力),否则可能在消费级GPU或CPU上效果有限。
- 注意力掩码优化:在llama.cpp中,通过自定义注意力掩码(attention mask)来实现前瞻逻辑,例如使用llama_batch和KV cache来管理状态。
lookahead示例的具体作用
这个示例是llama.cpp仓库通过PR #4207添加的(由ggerganov合并),目的是提供一个实际的lookahead decoding实现,便于开发者测试和理解该技术在llama.cpp框架中的应用。 其主要作用包括:
- 演示加速效果:在支持的硬件上(如NVIDIA A100或Apple Silicon),运行示例可以观察到token生成速度提升。例如,使用Mistral-7B模型测试时,标准main示例生成210 tokens需约2.6秒,而lookahead示例在某些配置下可能更快,但实际取决于硬件(在Apple Silicon上未观察到明显加速,因为计算规模小)。
- 教育和开发练习:它作为一个起点,帮助用户熟悉llama.cpp的核心API,如KV cache管理(存储注意力键-值对以复用计算)和batched decoding(批量解码,用于并行处理多个序列)。相关issue #4226建议基于lookahead、speculative和batched示例扩展到prompt lookup decoding,进一步强化这一教育作用。
- 测试和优化:示例支持命令行参数,如-m(模型路径)、-p(提示)、-ngl(GPU层数)、–seed(随机种子)。它使用ggml_init_cublas等初始化CUDA支持,并通过llama_model_loader加载GGUF模型。生成过程涉及prompt eval、eval和采样时间统计,便于基准测试。
如何使用
- 编译:在llama.cpp仓库中,使用make命令编译(若支持CUDA,添加LLAMA_CUBLAS=1)。
- 运行示例:例如,./lookahead -m path/to/model.gguf -p “Your prompt” -ngl 35 –seed 1。
- 如果在A100 GPU上运行,可能观察到生成中断或加速效果;若在Mac M1系列,可能需处理编译bug(如issue #5236所述)。
局限性
- 硬件依赖:需要高FLOPS硬件,大batch解码在低端设备上可能不加速,甚至变慢。
- 当前状态:示例主要针对LLaMA模型,量子化模型(如Q8_0)支持良好,但未针对所有后端(如SYCL)优化(issue #9505提到性能问题)。
- 扩展:issue #4226讨论了添加prompt-lookup-decoding变体,但尚未合并。
总体而言,lookahead示例是llama.cpp中一个实验性工具,旨在探索先进解码技术,推动本地LLM推理的效率提升。如果你想深入,可以查看仓库的PR和issue,或直接阅读代码以了解实现细节。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/10028