LLM 如何生成文本?
更多AI科技访问 https://www.2img.ai
更多AIGC能力访问 https://www.2video.cn
微信小程序 字形绘梦
Prompt
一切都始于提示。提示可以是我们希望 LLM 为我们完成的简单原始字符串,也可以是允许 LLM 进行聊天或使用外部工具的复杂结构。无论我们输入什么,它通常都是人类可读的格式,并使用特殊的“标签”(通常类似于 XML 标签)来分隔提示的各个部分。
我们已经看到了用于聊天完成的提示示例,由以下人员提供llama-server:
<|im_start|>system
You are a helpful assistant<|im_end|>
<|im_start|>user
Hello<|im_end|>
<|im_start|>assistant
Hi there<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
(如果您想知道那些有趣的 <| 和 |> 符号是什么– 它们是 Fira Code 字体中由|、>和<字符组成的连字)
Tokenization
LLM 不像我们一样理解人类语言。我们使用单词和标点符号来组成句子——LLM 使用可以被理解为等价物的标记。文本生成的第一步是通过执行快速标记化来打破语言障碍。标记化是将输入文本(以人类可读的格式)转换为 LLM 可以处理的标记数组的过程。标记是简单的数值,通过词汇表,它们可以轻松地映射到相应的字符串表示形式(至少在 BPE 模型中是这样,其他模型就不知道了)。事实上,这些词汇表可以在 SmolLM2 存储库的tokenizer.json文件中找到!该文件还包含一些对LLM具有特殊含义的特殊标记的元数据。其中一些标记代表元信息,例如消息的开始和结束。其他标记可以通过提供用于分隔对话各个部分(系统提示、用户消息、LLM 响应)的标签来允许 LLM 与用户聊天。我还看到了 LLM 模板中的工具调用功能,理论上应该允许 LLM 使用外部工具,但我还没有测试过它们(查看 Qwen2.5 和 CodeQwen2.5 了解具有这些功能的示例模型)。
我们可以使用llama-serverAPI 对一些文本进行标记,并查看翻译后的效果。希望您已经了解curl。
curl -X POST -H "Content-Type: application/json" -d '{"content": "hello world! this is an example message!"}' http://127.0.0.1:8080/tokenize
对于 SmolLM2,响应应如下:
{"tokens":[28120,905,17,451,314,1183,3714,17]}复制
我们可以粗略地将其翻译为:
- 28120 – 你好
- 905——世界
- 17——!
- 451 – 这个
- 314 – 是
- 354 – 一个
- 1183 – 例如
- 3714 – 消息
- 17——!
我们可以将此 JSON 传回/detokenize端点以获取原始文本:
curl -X POST -H "Content-Type: application/json" -d '{"tokens": [28120,905,17,451,314,354,1183,3714,17]}' http://127.0.0.1:8080/detokenize{"content":"hello world! this is an example message!"}Dank Magick (feeding the beast)
说实话,我不知道这一步到底发生了什么,但我会尽力用简单且非常近似的术语来解释。输入是标记化的提示。此提示被输入到 LLM,由于必须执行大量的矩阵运算才能满足这个数字野兽的要求,因此消化过程需要大量的处理时间。在消化完提示后,LLM 开始与我们“对话”。LLM 通过输出其字典中所有标记的概率分布来“对话”。此分布是一个包含标记值及其被用作下一个标记的概率的对的列表。现在,理论上我们可以使用具有最高概率的单个标记并完成生成,但这不是最好的做事方式。
令牌采样Token sampling
这一步或许是我们最感兴趣的一步,因为我们可以控制它的每一个参数。和往常一样,我建议在处理 Demons 的原始输出时要谨慎——无论是否是数字格式,处理不当都可能导致意外发生。采样器用于从原始 LLM 输出中选择“最佳”标记。它们的工作原理是将所有可用的标记精简为一个。需要注意的是,并非每个采样器都会直接执行此操作(例如,Top-K 会选择 K 个标记),但在标记化最终会得到一个标记。
去标记化Detokenization
生成的代币必须转换回人类可读的形式,因此必须进行去代币化。这是最后一步。万岁,我们驯服了这头数字野兽,并迫使它开口说话。我之前曾担心过这会给人类带来什么后果,但现在我们做到了,373 1457 260 970 1041 3935。
llama.cpp 中可用的 LLM 配置选项和采样器列表
系统消息- 通常,与LLM的对话始于一条“系统”消息,该消息指示LLM如何操作。这可能是最容易使用的工具,但却可以显著改变模型的行为。我的建议是,尽可能多地为你的申请提供有用的信息和精确的行为描述,以最大限度地提高LLM的输出质量。你可能认为,赋予数字恶魔尽可能多的知识可能会导致不好的事情发生,但我们的现实世界还没有崩溃,所以我认为目前情况还好。
温度- 根据llama.cpp文档,“通过影响输出标记的概率分布来控制生成文本的随机性。值越高,随机性越强;值越低,集中性越强”。这里我没什么可补充的,它控制着法学硕士(LLM)的“创造力”。值越高,输出就越随机、越“有创意”,但过度加热可能会导致幻觉,并且在某些情况下,会发出摧毁理智的尖叫声。首先,请将其保持在 0.2-2.0 的范围内,并保持正值且非零。
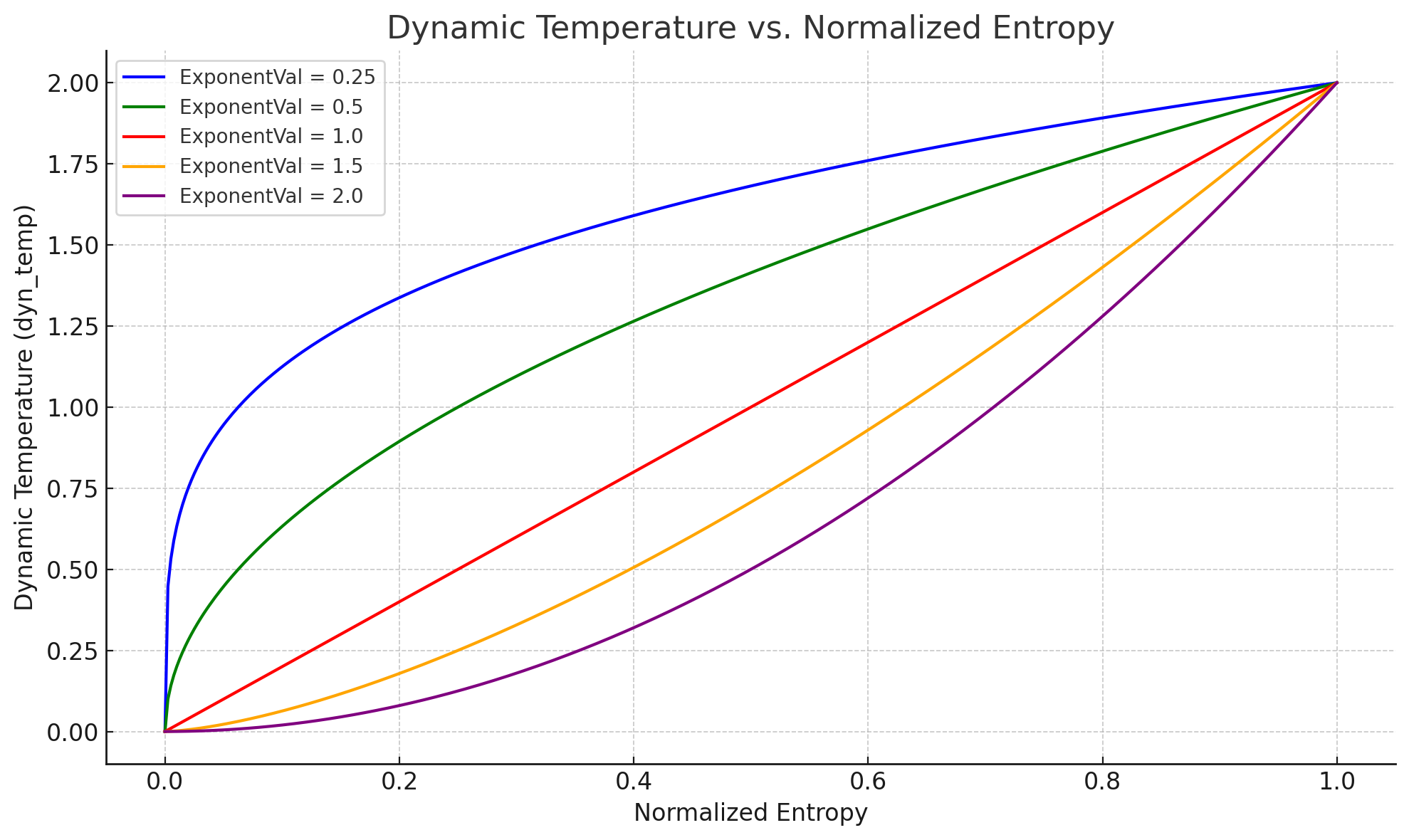
动态温度- 动态温度采样是温度采样器的一个补充。链接的文章对此进行了详细描述,而且篇幅很短,因此我强烈建议您阅读——我实在无法更好地解释它。Reddit上也有一篇帖子,其中有该算法作者的更多解释。但是,如果文章无法访问,该算法的简短解释是:它根据生成的 token 的熵来调整其温度。这里的熵可以理解为 LLM 对生成的 token 的置信度的倒数。较低的熵意味着 LLM 对其预测的置信度更高,因此熵较低的 token 的温度也应该较低。高熵则相反。实际上,这种采样可以激发创造力,同时防止在较高温度下产生幻觉。我强烈建议您测试一下,因为它通常默认处于禁用状态。启用后,可能需要对其他采样器进行一些额外的调整,才能获得最佳效果。动态温度采样器的参数如下:
Dynatemp 范围- 要添加/减去的动态温度范围
Dynatemp 指数- 改变指数会以以下方式改变动态温度(图片厚颜无耻地从之前链接的重返大气层文章中窃取):
- Top-K – Top-K 采样是“仅保留最可能的标记”算法的别称
K。值越高,文本的多样性就越高,因为在生成响应时有更多标记可供选择。 - Top-P – Top-P 采样,也称为核采样,根据
llama.cpp文档“将标记限制为那些累计概率至少为 的标记p”。用人类语言来说,这意味着 Top-P 采样器将标记及其概率列表作为输入(请注意,它们的累计概率之和按定义等于 1),并从该列表中返回具有最高概率的标记,直到它们的累计概率之和大于或等于p。或者换句话说,p值改变了 Top-P 采样器返回的标记的百分比。例如,当p等于 0.7 时,采样器将返回具有最高概率的 70% 的输入标记。我发现了一篇关于温度、Top-K 和 Top-P 采样的非常好的文章,如果您想了解更多信息,可以推荐它。 - Min-P – Min-P 采样,根据
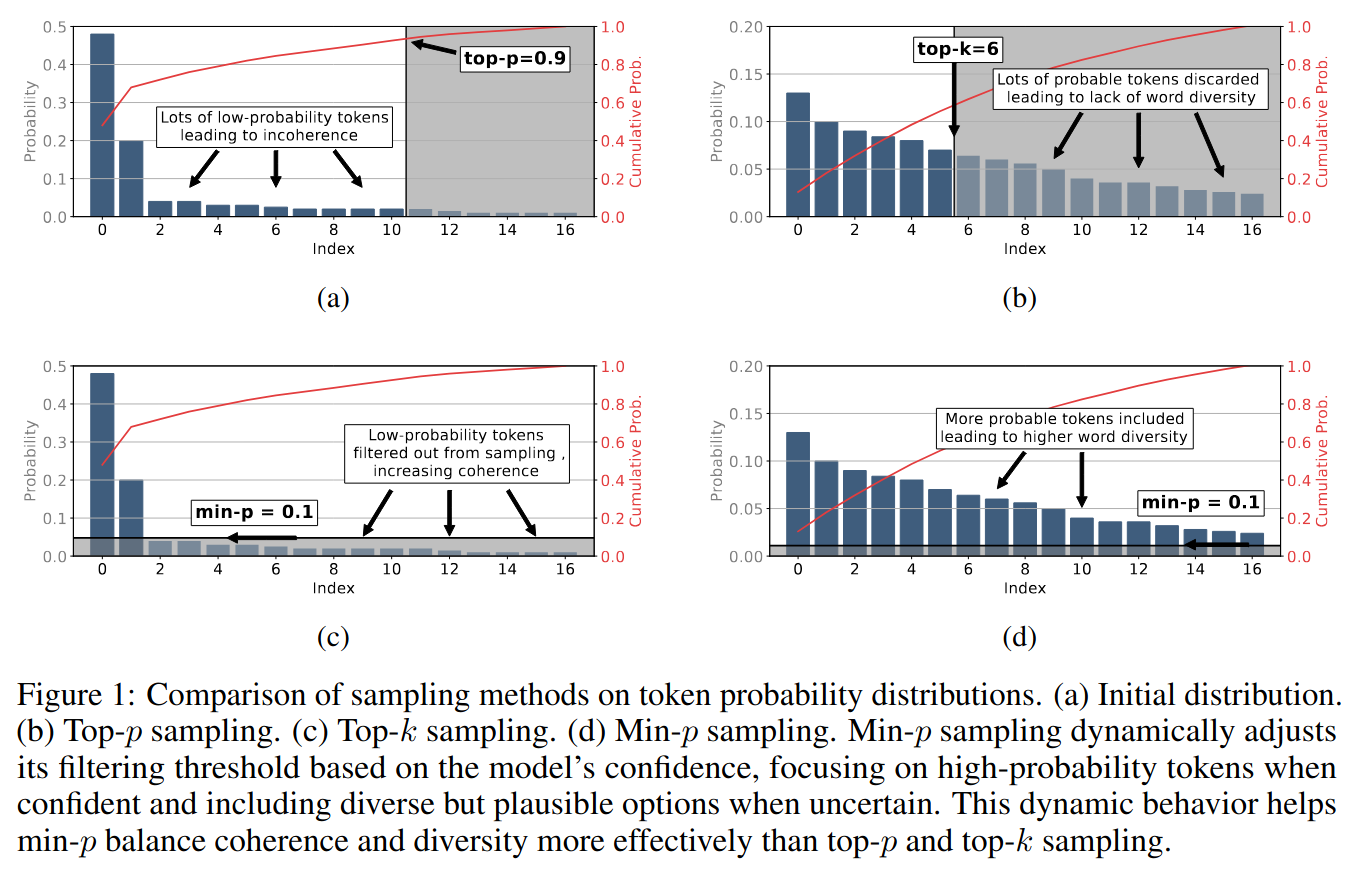
llama.cpp文档“根据一个 token 被考虑的最小概率(相对于最可能 token 的概率)来限制 token”。有一篇论文解释了这个算法(它也包含大量其他 LLM 相关内容的引用,值得一读)。该论文中的图 1 很好地展示了每种采样算法对 token 概率分布的影响:
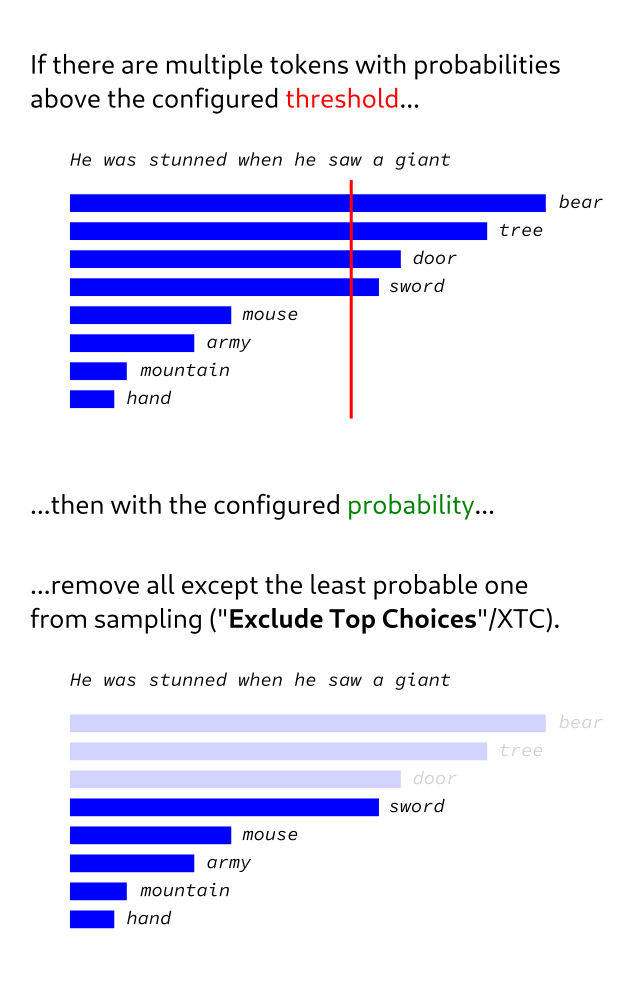
- 排除最佳选择 (XTC) – 这是一个比较特别的采样器,因为它的工作原理与大多数其他采样器略有不同。引用作者的话来说,在某些情况下,它不会修剪可能性最小的标记,而是将可能性最大的标记从考虑范围中移除。 详细描述可以在包含实现的 PR中找到。我建议你读一下,因为我实在想不出比这更好的解释,但这确实是一个很好的解释。 不过,我可以从链接的 PR 中偷用这张图片来大致展示 XTC 的功能:
- XTC 采样器的参数如下:
- XTC 阈值– 顶级标记的概率截止阈值,在(0,1)范围内。
- XTC 概率– XTC 采样应用的概率在 [0, 1] 范围内,其中 0 = XTC 禁用,1 = XTC 始终启用。
- 局部典型采样(典型 P) ——根据
llama.cpp文档“根据对数概率和熵的差异对标记进行排序和限制”。我……说实话,我不知道它到底是怎么运作的。我尝试阅读链接的论文,但我的智力不足以理解它,因此无法对其进行描述。Reddit 上也有人遇到同样的问题,所以我建议大家去那里看看评论。我很少使用这种采样方法,所以我也无法从经验中得出任何结论,所以——我们继续吧。 - DRY – 此采样器用于防止不必要的标记重复。简而言之,它会尝试检测生成的文本中重复的标记序列,并降低产生重复的标记的概率。像往常一样,我建议阅读链接的 PR 以获取详细解释,并且像往常一样,我从中窃取了一张图来展示 DRY 的作用:

- 我还将引用此采样器的简短说明: 标记的惩罚计算为
multiplier * base ^ (n - allowed_length),其中n是与输入末尾匹配的该标记之前序列的长度,并且multiplier,,base和allowed_length是可配置参数。如果匹配序列的长度小于allowed_length,则不应用惩罚。DRY 采样器的参数为:- DRY 乘数– 参见上面的解释
- 干燥基底– 参见上面的解释
- DRY 允许的长度– 参见上文解释。引用
llama.cpp文档:重复次数超过此限制的词法单元将受到指数级增加的惩罚。 - DRY 惩罚最后 N 个– 应扫描多少个标记以进行重复。 -1 = 整个上下文, 0 = 禁用。
- DRY 序列断开符 – 用于分隔符合 DRY 规范的句子各部分的字符。默认
llama.cpp值为('n', ':', '"', '*')。
- Mirostat是一种新颖的采样算法,它能够覆盖 Top-K、Top-P 和 Traditional-P 采样器。它是一种替代采样器,能够生成具有可控困惑度(熵)的文本,这意味着我们可以控制模型预测的确定性。这不会产生重复文本(在低困惑度场景中会发生)或不连贯输出(在高困惑度场景中会发生)的副作用。Mirostat 的配置参数如下:
- Mirostat 版本– 0 = 禁用,1 = Mirostat,2 = Mirostat 2.0。
- Mirostat 学习率(η,eta) ——指定模型收敛到所需困惑度的速度。
- Mirostat 目标熵 (τ, tau) – 期望的困惑度。根据模型的不同,该值不宜过高,否则可能会降低模型的性能。
- 最大标记– 我认为这是不言自明的。-1 使 LLM 生成直到它决定句子的结束(通过返回句子结束标记),或者上下文已满。
- 重复惩罚– 重复惩罚算法(不要与 DRY 混淆)只是减少了生成文本中已存在的标记被重复使用的机会。通常,重复惩罚算法仅限于
N上下文的最后一个标记。在这种情况下llama.cpp(我会稍微简化一下),它的工作原理如下:首先,它会为最后一个N标记创建一个频率图。然后,将每个标记的当前逻辑偏差除以repeat_penalty值。默认情况下,它通常设置为 1.0,因此要启用重复惩罚,应将其设置为 >1。最后,根据频率图应用频率和存在惩罚。每个标记的惩罚等于(token_count * frequency_penalty) + (presence_penalty if token_count > 0)。惩罚表示为逻辑偏差,可以在 [-100, 100] 范围内。负值会降低标记出现在输出中的概率,而正值会增加它。重复惩罚的配置参数如下:- 重复最后 N — 从上下文末尾考虑重复惩罚的标记数量。
- 重复惩罚–
repeat_penalty上面描述的参数,如果相等,1.0则重复惩罚被禁用。 - 存在惩罚——
presence_penalty来自上述等式的论证。 - 频率惩罚——
frequency_penalty来自上述等式的论据。
其他文献:
在其他采样器设置中,我们可以找到采样队列配置。正如我之前提到的,采样器是链式应用的。在这里,我们可以配置它们的应用顺序,并选择使用哪个采样器。该设置使用采样器的简称,映射如下:
d– 干燥k– 前K个y– 典型-Pp– 顶部-Pm– Min-Px– 排除最佳选择 (XTC)t– 温度
我上面列出的某些采样器和设置可能在 Web UI 配置中缺失(例如 Mirostat),但它们都可以通过环境变量、llama.cpp二进制文件的 CLI 参数或 llama.cpp 服务器 API 进行配置。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9995