
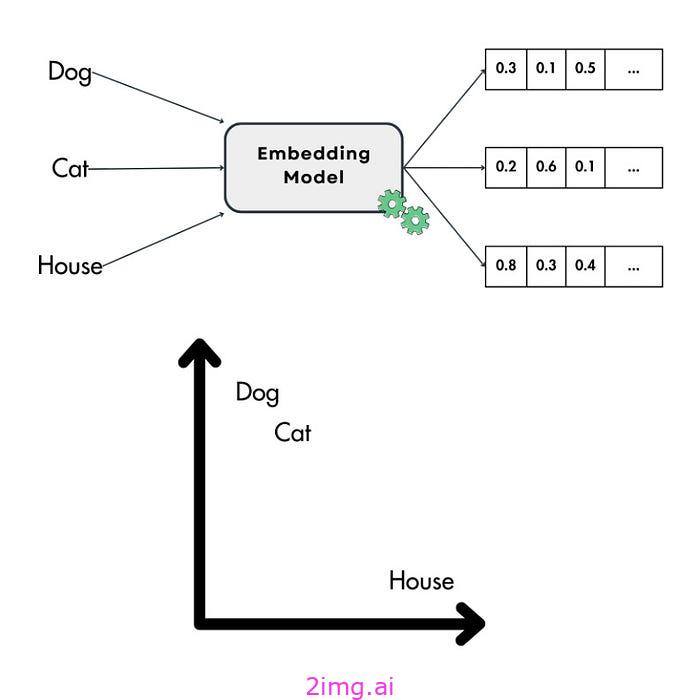
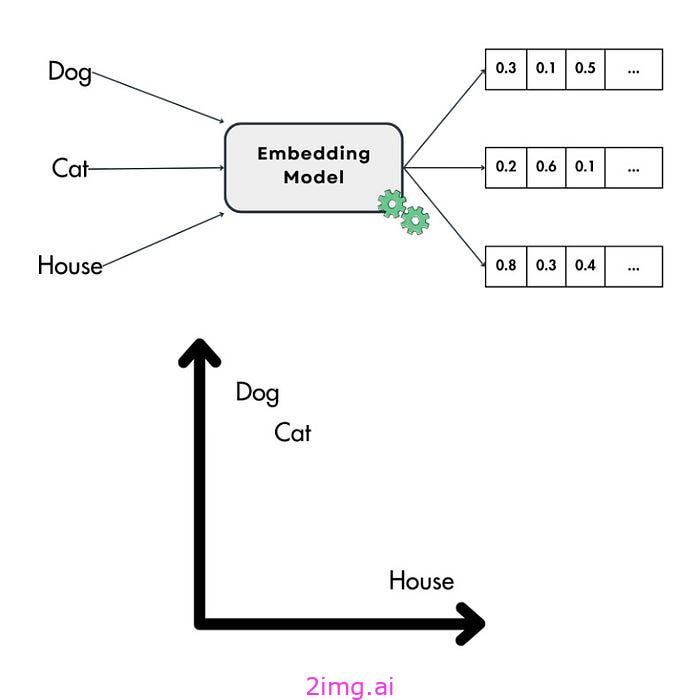
嵌入是许多 AI 和 ML 应用程序的基石,例如 GenAI、RAG、推荐系统、编码高维分类变量(例如 LLM 的输入标记)等。
例如,在 RAG 应用程序中,它们在从向量数据库索引和检索数据方面发挥着关键作用,直接影响检索步骤。
它们以某种形式存在于几乎每个 ML 领域。
因此,对嵌入的工作方式有强烈的直觉是一项强大的技能。
在本文中,您将了解嵌入的基础知识,例如:
- 它们是什么
- 它们是如何工作的
- 它们为何如此强大
- 它们是如何被创造出来的。
目录
- 什么是嵌入
- 为什么嵌入如此强大
- 嵌入是如何创建的?
- 嵌入的应用
#1. 什么是嵌入
想象一下,你正在尝试教计算机理解世界。嵌入就像一个特殊的翻译器,可以将这些东西转换成数字代码。不过,这种代码并不是随机的,因为相似的单词或项目最终会得到彼此接近的代码。它就像一张地图,具有相似含义的单词聚集在一起。
考虑到这一点,更理论化的定义是,嵌入是连续向量空间中编码为向量的对象的密集数值表示,例如推荐系统中的单词、图像或项目。这种转换有助于捕捉对象之间的语义含义和关系。例如,在自然语言处理 (NLP) 中,嵌入将单词转换为向量,其中语义相似的单词在向量空间中紧密排列在一起。
一种流行的方法是将嵌入可视化,以了解和评估它们的几何关系。由于嵌入通常有 2 或 3 个以上的维度,通常在 64 到 2048 之间,因此您必须将它们再次投影到 2D 或 3D。
例如,您可以使用UMAP,这是一种众所周知的降维方法,在将嵌入投影到 2D 或 3D 时保留点之间的几何属性。可视化向量时另一种流行的降维算法是t-SNE。然而,与 UMAP 相比,它更具随机性,并且不保留点之间的拓扑关系。

#2. 为何嵌入如此强大
首先,机器学习模型只处理数值。处理表格数据时这不是问题,因为数据通常为数字形式或可以轻松处理为数字。当我们想要将单词、图像或音频数据输入模型时,嵌入非常有用。
例如,在使用 Transformer 模型时,您会对所有文本输入进行标记,其中每个标记都有一个与之关联的嵌入。这个过程的优点在于它的简单性 – Transformer 的输入是一系列嵌入,可以通过神经网络的密集层轻松而自信地进行解释。
基于此示例,您可以使用嵌入来编码任何分类变量并将其提供给 ML 模型。但为什么不使用其他简单的方法,例如独热编码?处理具有高基数的分类变量(例如语言词汇表)时,使用其他传统方法会遭受维数灾难。例如,如果您的词汇表有 10000 个标记,那么应用独热编码后,只有一个标记的长度为 10000。如果输入序列有 N 个标记,那将成为 N * 10000 个输入参数。如果 N >= 100,则在输入文本时,输入通常会太大而无法使用。其他不受维数灾难影响的经典方法(例如散列)的另一个问题是,您会丢失向量之间的语义关系。
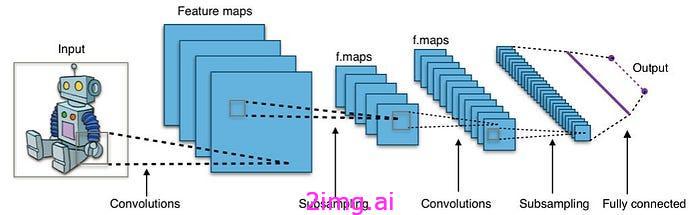
其次,嵌入输入会减小其维度大小,并将其所有语义含义压缩为一个密集向量。这是处理图像时非常流行的技术,其中 CNN 编码器模块将高维含义映射到嵌入中,然后由执行分类或回归步骤的 CNN 解码器进行处理。
下图显示了典型的 CNN 布局。想象一下每层内的小方块。这些是“接受域”。每个方块将信息馈送到前一层的单个神经元。当您穿过网络时,会发生两件关键的事情:
- 缩小图片:特殊的“子采样”操作使图层变小,聚焦于重要细节。
- 学习特征:另一方面,随着网络从图像中学习更复杂的特征,“卷积”操作实际上会增加层的大小。
最后,末端的全连接层将所有这些处理过的信息转换成最终的矢量嵌入,即数字图像表示。
#3. 嵌入是如何创建的?
嵌入由深度学习模型创建,该模型理解输入的上下文和语义并将其投影到连续向量空间中。
各种深度学习模型都可用于创建嵌入,具体取决于数据输入类型。因此,在选择嵌入模型之前,了解您的数据以及您需要从中获得什么至关重要。
例如,在处理文本数据时,用于为词汇表创建嵌入的早期方法之一是Word2Vec和GloVe。这些方法至今仍是用于较简单应用程序的流行方法。
另一种流行的方法是使用仅编码器的 Transformer,例如BERT,或其系列中的其他方法,例如RoBERTa。这些模型利用 Transformer 架构的编码器将您的输入智能地投影到密集向量空间中,稍后可用作嵌入。
为了快速计算 Python 中的嵌入,您可以方便地利用 Sentence Transformers Python 包(也可在 HuggingFace 的 transformer 包中使用)。此工具提供了用户友好的界面,使嵌入过程变得简单而高效。
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model.
model = SentenceTransformer("all-MiniLM-L6-v2")
sentences = ["The dog sits outside waiting for a treat.", "I am going swimming.", "The dog is swimming."]
# 2. Calculate embeddings.
embeddings = model.encode(sentences)
print(embeddings.shape)
# Output: [3, 384]
# 3. Calculate the embedding similarities using cosine similarity.
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# Output:
# tensor([[ 1.0000, -0.0389, 0.2692],
# [-0.0389, 1.0000, 0.3837],
# [ 0.2692, 0.3837, 1.0000]])
# similarities[0, 0] = The similarity between the first sentence and itself.
# similarities[0, 1] = The similarity between the first and second sentence.
# similarities[2, 1] = The similarity between the third and second sentence.性能最佳的嵌入模型会随着时间和您的具体用例而变化。您可以在HuggingFace 上的Massive Text Embedding Benchmark (MTEB)上找到特定模型。根据您的需求,您可以考虑性能最佳的模型、准确率最高的模型或内存占用最小的模型。此决定完全取决于您的要求(例如准确率、硬件等)。但是,HuggingFace 和 SentenceTransformer 使不同模型之间的切换变得简单。因此,您始终可以尝试各种选项。
处理图像时,您可以使用卷积神经网络(CNN) 嵌入图像。流行的 CNN 网络基于ResNet架构。但是,我们不能直接将图像嵌入技术用于音频录制。相反,我们可以创建音频的视觉表示,例如频谱图,然后将图像嵌入模型应用于这些视觉效果。这使我们能够以计算机可以理解的方式捕捉图像和声音的本质。
通过利用CLIP之类的模型,您实际上可以将一段文本和一张图片嵌入到同一个向量空间中。这样您就可以使用句子作为输入来查找相似的图像,反之亦然,这证明了CLIP的实用性。
from io import BytesIO
import requests
from PIL import Image
from sentence_transformers import SentenceTransformer
# Load an image with a crazy cat.
response = requests.get(
"https://github.com/PacktPublishing/LLM-Engineering/blob/main/images/crazy_cat.jpg?raw=true"
)
image = Image.open(BytesIO(response.content))
# Load CLIP model.
model = SentenceTransformer("clip-ViT-B-32")
# Encode the loaded image.
img_emb = model.encode(image)
# Encode text descriptions.
text_emb = model.encode(
[
"A crazy cat smiling.",
"A white and brown cat with a yellow bandana.",
"A man eating in the garden.",
]
)
print(text_emb.shape)
# Output: (3, 512)
# Compute similarities.
similarity_scores = model.similarity(img_emb, text_emb)
print(similarity_scores)
# Output: tensor([[0.3068, 0.3300, 0.1719]])这里我们简单介绍了一下如何计算嵌入。具体实现的范围很广,但重要的是要知道,大多数数字数据类别都可以计算嵌入,例如单词、句子、文档、图像、视频、图形等。
重要的是要理解,当您需要计算两个不同数据类别之间的距离时,必须使用专门的模型,例如句子向量和图像向量之间的距离。这些模型旨在将两种数据类型投影到同一个向量空间中,例如 CLIP,以确保准确的距离计算。
#4. 嵌入的应用
由于使用 RAG 的生成式 AI 革命,嵌入在信息检索任务中变得极为流行,例如文本、代码、图像和音频的语义搜索以及代理的长期记忆。
但在 Gen AI 出现之前,嵌入已经广泛用于:
- 表示输入到 ML 模型的分类变量(例如词汇标记)。
- 推荐系统通过对用户和项目进行编码并找到它们之间的关系。
- 聚类和异常值检测。
- 使用UMAP等算法进行数据可视化。
- 使用嵌入作为特征进行分类。
- 通过比较每个类的嵌入并选择最相似的一个来进行零样本分类。
全面了解 RAG 如何工作的最后一步是检查向量数据库以及它们如何利用嵌入来检索数据。
结论
在本文中,我们探讨了嵌入的基础知识。
通过对嵌入的直观理解,我们理解了为什么它们是任何 ML 工程师的基本技能。它们是几乎所有 ML 应用程序的基石,例如 GenAI、RAG 和推荐系统项目。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/5961







