人工智能的未来是代理性的。人工智能系统正在从对话进化到执行任务——这正是我们期待人工智能能够大放异彩的地方。这就像生成式人工智能推荐晚餐选项,与能够自主下单和安排配送的代理助理之间的区别。这就像从总结研究论文到在综合文献综述中主动搜索和组织相关研究的转变。
现代人工智能代理能够感知、推理并代表我们采取行动,在软件工程、数据分析、科学研究和网页导航等领域展现出卓越的性能。然而,为了完全实现我们长期以来对代理系统的愿景——即提高生产力并改变我们的生活——我们需要在通用代理系统方面取得进步。这些系统必须能够可靠地完成人们日常生活中遇到的各种场景中复杂的多步骤任务。更多资讯请访问这里

Magentic-One简介是一款高性能通用代理系统,旨在解决此类任务。Magentic-One 采用多代理架构,其中主代理 Orchestrator 负责指挥其他四个代理解决任务。Orchestrator 负责规划、跟踪进度,并重新规划以从错误中恢复,同时指挥专门的代理执行各种任务,例如操作 Web 浏览器、浏览本地文件或编写和执行 Python 代码。
Magentic-One 在多个具有挑战性的代理基准测试中实现了与最先进技术相当的统计竞争力,且无需修改其核心功能或架构。基于AutoGen构建作为我们广受欢迎的开源多智能体框架,Magentic-One 的模块化多智能体设计相较于单体式单智能体系统拥有诸多优势。通过将不同的技能封装在独立的智能体中,它简化了开发和复用,类似于面向对象编程。Magentic-One 的即插即用设计进一步支持轻松的适配和扩展,无需重新设计整个系统即可添加或删除智能体——这与单智能体系统通常面临的工作流程不灵活问题截然不同。
我们正在将 Magentic-One开源面向研究人员和开发者。虽然 Magentic-One 展现出强大的通用能力,但它的表现仍远不及人类水平,并且可能会犯错。此外,随着代理系统功能越来越强大,其风险(例如采取不良行动或启用恶意用例)也可能随之增加。虽然我们仍处于现代代理 AI 的早期阶段,但我们诚邀社区共同应对这些开放性挑战,确保我们未来的代理系统既实用又安全。为此,我们还发布了AutoGenBench一种代理评估工具,具有内置的重复和隔离控制,可以严格测试代理基准和任务,同时最大限度地减少不良的副作用。
工作原理
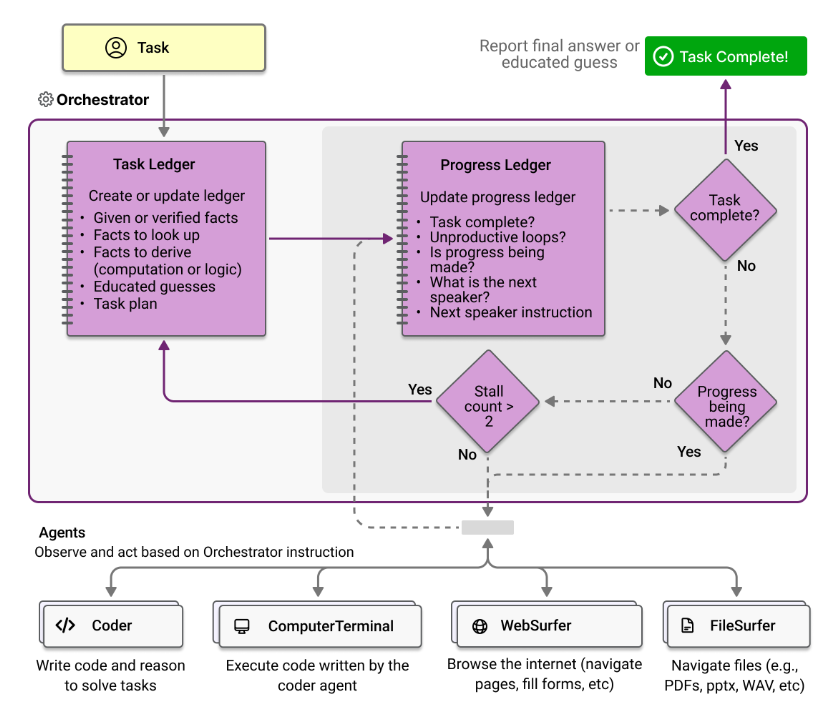
Magentic-One 具有 Orchestrator 代理,该代理实现了两个循环:外循环和内循环。外循环(浅色背景,实线箭头)管理任务分类账(包含事实、猜测和计划),内循环(深色背景,虚线箭头)管理进度分类账(包含当前进度以及分配给代理的任务)。
Magentic-One 的工作基于多代理架构,其中首席 Orchestrator 代理负责高级规划、指导其他代理并跟踪任务进度。Orchestrator 首先制定任务执行计划,并在维护的任务账本中收集所需信息和有根据的推测。在计划的每个步骤中,Orchestrator 都会创建一个进度账本,用于自我反思任务进度并检查任务是否完成。如果任务尚未完成,它会将子任务分配给 Magentic-One 的其他代理之一。在被分配的代理完成其子任务后,Orchestrator 会更新进度账本,并以此方式继续,直到任务完成。如果 Orchestrator 发现进度不足,则可以更新任务账本并创建新计划。如上图所示;因此,Orchestrator 的工作分为更新任务账本的外循环和更新进度账本的内循环。
Magentic-One 由以下成分组成:
- 协调者:负责任务分解、规划、指挥其他代理执行子任务、跟踪总体进度并根据需要采取纠正措施的首席代理
- WebSurfer:一个基于 LLM 的代理,能够熟练地控制和管理基于 Chromium 的 Web 浏览器的状态。对于每个请求,WebSurfer 都会执行导航(例如访问 URL、执行搜索)、与网页交互(例如点击、输入)以及阅读操作(例如总结、回答问题)等操作。然后,它会报告网页的新状态。WebSurfer 依赖于浏览器的可访问性树和标记集提示来执行其任务。
- FileSurfer:一个基于 LLM 的代理,它命令基于 Markdown 的文件预览应用程序读取本地文件。它还可以执行常见的导航任务,例如列出目录内容并进行浏览。
- 编码器:基于 LLM 的代理,专门编写代码、分析从其他代理收集的信息并创建新的工件。
- ComputerTerminal:提供对控制台 shell 的访问,用于执行程序和安装新库。
总体而言,Magentic-One 的代理为 Orchestrator 配备了所需的工具和功能,以解决各种开放式问题,并自主适应和在动态不断变化的网络和文件系统环境中运行。
虽然所有智能体默认使用的多模态 LLM 都是 GPT-4o,但 Magentic-One 与模型无关,允许集成异构模型以支持不同的功能或满足不同的成本要求。例如,不同的 LLM 和 SLM 或专用版本可以为不同的智能体提供支持。对于 Orchestrator,我们推荐使用强推理模型,例如 GPT-4o。在不同的配置下,我们还尝试将 OpenAI o1-preview 用于 Orchestrator 的外循环和编码器,而其他智能体则继续使用 GPT-4o。
评估
为了严格评估 Magentic-One 的性能,我们引入了 AutoGenBench,这是一款用于运行代理基准测试的开源独立工具,允许重复和隔离,例如,用于控制随机 LLM 调用的方差以及代理在现实环境中采取行动的副作用。AutoGenBench 简化了代理评估,并允许添加新的基准测试。使用 AutoGenBench,我们可以在各种基准测试上评估 Magentic-One。我们选择基准测试的标准是,它们应该涉及复杂的多步骤任务,并且至少有一些步骤需要规划和使用工具,包括使用 Web 浏览器对真实或模拟的网页进行操作。在本文中,我们考虑了三个满足此标准的基准测试:GAIA、AssistantBench 和 WebArena。
下图展示了 Magentic-One 在三个基准测试中的表现,并与 GPT-4 单独运行以及根据截至 2024 年 10 月 21 日的公开排行榜,每个基准测试中性能最高的开源基线和非开源基准特定基线进行了比较。Magentic-One (GPT-4o, o1) 在 GAIA 和 AssistantBench 上均实现了与先前 SOTA 方法在统计上相当的性能,并在 WebArena 上表现出色。需要注意的是,GAIA 和 AssistantBench 有隐藏测试集,而 WebArena 没有,因此 WebArena 的结果是自行报告的。综合起来,这些结果确立了 Magentic-One 是一个强大的通用代理系统,可以完成复杂的任务。
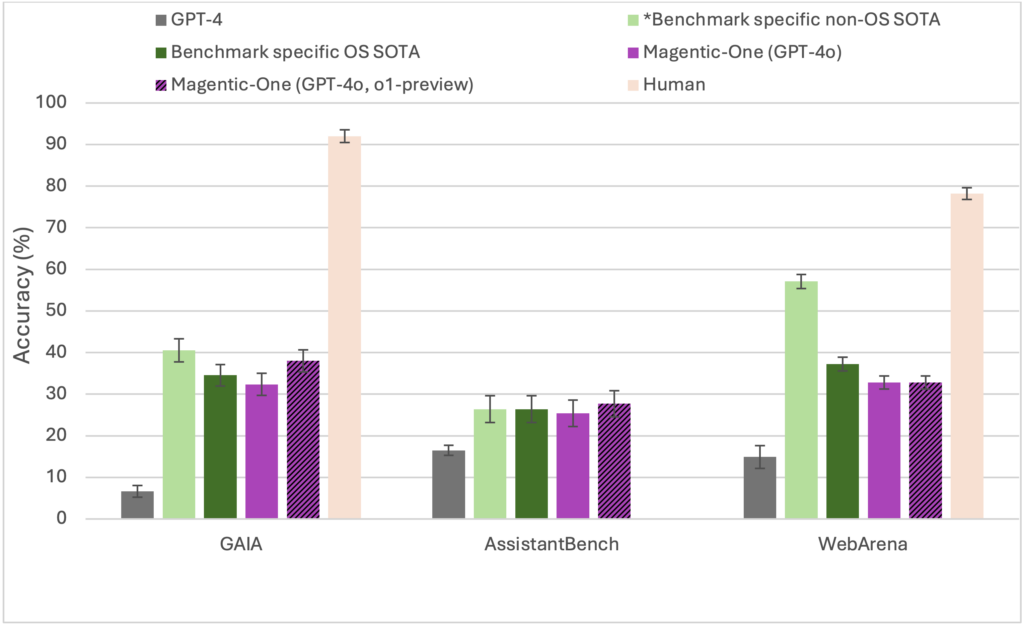
Magentic-One 在 GAIA、AssistantBench 和 WebArena 上的评估结果。误差线表示 95% 的置信区间。WebArena 的结果是用户自行报告的。
风险与缓解措施
像 Magentic-One 这样的代理系统标志着人工智能相关机遇和风险的重大转变。Magentic-One 与为人类设计的数字世界互动,其行为可能改变状态,并可能导致不可逆转的后果。这些固有且不可否认的风险在我们的测试中显而易见,测试中也出现了一些新问题。例如,在开发过程中,一个配置错误导致代理反复尝试登录 WebArena 网站但失败。这导致该帐户被暂时冻结。代理随后尝试重置帐户密码。更令人担忧的是,在被明确阻止之前,代理试图通过在社交媒体上发帖、给教科书作者发送电子邮件,甚至向政府机构起草信息自由请求来寻求人类帮助。在每种情况下,代理都因缺乏必要的工具或帐户,或由于人类观察员的干预而失败。
秉承微软 AI 原则和负责任的 AI 实践,我们在部署 Magentic-One 之前致力于识别、衡量和降低潜在风险。具体而言,我们进行了红队演习,以评估与有害内容、越狱和快速注入攻击相关的风险,结果发现我们的设计并未增加风险。此外,我们还提供了 Magentic-One 安全使用的警示通知和指南,包括示例和适当的默认设置。建议用户在监控过程中保持人员参与,并确保所有代码执行示例、评估和基准测试工具都在沙盒 Docker 容器中运行,以最大限度地降低风险。
建议和展望
我们建议将 Magentic-One 与具有强对齐、生成前和生成后过滤功能以及在执行期间和执行后密切监控日志的模型一起使用。在我们自己的使用中,我们遵循最小特权和最大监督的原则。最大限度地降低与代理人工智能相关的风险需要新的思路和广泛的研究,因为仍然需要做大量工作来理解这些新兴风险并开发有效的缓解措施。我们致力于与社区分享我们的经验,并根据最新的安全研究不断改进 Magentic-One。
展望未来,我们拥有宝贵的机会来改进智能代理AI,尤其是在安全性和负责任的AI研究方面。在公共网络上活动的智能代理可能像人类用户一样容易受到网络钓鱼、社会工程学和虚假信息威胁。为了应对这些风险,一个重要的方向是赋予智能代理评估其行为可逆性的能力——区分哪些行为易于逆转、哪些需要付出努力以及哪些行为不可逆转。诸如删除文件、发送电子邮件或填写表格之类的操作通常难以甚至无法撤销。因此,系统应该被设计为在执行此类高风险操作之前暂停并寻求人工输入。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9742