以llama.cpp工具为例,介绍MacOS和Linux系统中,将模型进行量化并在本地CPU上部署的详细步骤。Windows则可能需要cmake等编译工具的安装(Windows用户出现模型无法理解中文或生成速度特别慢时请参考FAQ#6)。本地快速部署体验推荐使用经过指令精调的Alpaca模型,有条件的推荐使用8-bit模型,效果更佳。 下面以中文Alpaca-7B模型为例介绍,运行前请确保:
- 系统应有
make(MacOS/Linux自带)或cmake(Windows需自行安装)编译工具 - 建议使用Python 3.10以上编译和运行该工具
- 最新版llama.cpp添加了对GPU的支持,感兴趣的可以参考https://github.com/ggerganov/llama.cpp/discussions/915
更多资讯访问:

Step 1: 克隆和编译llama.cpp
运行以下命令对llama.cpp项目进行编译,生成./main和./quantize二进制文件。
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make
- Windows/Linux用户:推荐与BLAS(或cuBLAS如果有GPU)一起编译,可以提高prompt处理速度,参考:
- macOS用户:无需额外操作,llama.cpp已对ARM NEON做优化,并且已自动启用BLAS
Step 2: 生成量化版本模型
将合并模型(选择生成.pth格式模型)中最后一步生成的tokenizer.model文件放入zh-models目录下,模型文件consolidated.*.pth和配置文件params.json放入zh-models/7B目录下。请注意LLaMA和Alpaca的tokenizer.model不可混用(原因见训练细节)。目录结构类似:
llama.cpp/zh-models/
- 7B/
- consolidated.00.pth
- params.json
- tokenizer.model将上述.pth模型权重转换为ggml的FP16格式,生成文件路径为zh-models/7B/ggml-model-f16.bin。
python convert.py zh-models/7B/
进一步对FP16模型进行4-bit量化,生成量化模型文件路径为zh-models/7B/ggml-model-q4_0.bin。不同量化方法的性能对比见本文最后。
./quantize ./zh-models/7B/ggml-model-f16.bin ./zh-models/7B/ggml-model-q4_0.bin q4_0
Step 3: 加载并启动模型
运行./main二进制文件,-m命令指定GGML格式模型。以下是命令示例(并非最优参数):
./main -m zh-models/7B/ggml-model-q4_0.bin –color -f prompts/alpaca.txt -ins -c 2048 –temp 0.2 -n 256 –repeat_penalty 1.1
在提示符 > 之后输入你的prompt,cmd/ctrl+c中断输出,多行信息以\作为行尾。如需查看帮助和参数说明,请执行./main -h命令。下面介绍一些常用的参数:
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-ins 启动类ChatGPT对话交流的instruction运行模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-n 控制回复生成的最大长度(默认:128)
-b 控制batch size(默认:8),可适当增加
-t 控制线程数量(默认:4),可适当增加
--repeat_penalty 控制生成回复中对重复文本的惩罚力度
--temp 温度系数,值越低回复的随机性越小,反之越大
--top_p, top_k 控制解码采样的相关参数更详细的官方说明请参考:https://github.com/ggerganov/llama.cpp/tree/master/examples/main
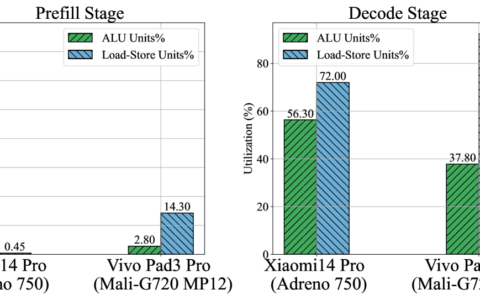
关于量化方法选择及推理速度
下表给出了不同量化方法的相关统计数据供参考。推理模型为中文Alpaca-Plus-7B、Alpaca-Plus-13B,测试设备为M1 Max芯片(8x性能核心,2x能效核心)。速度方面报告的是eval time,即模型回复生成的速度。更多关于量化参数的介绍可参考llama.cpp量化统计表。
相关结论:
- 默认的量化方法为q4_0,虽然速度最快但损失也是最大的,其余方法各有利弊,按实际情况选择
- 综合推荐(仅供参考):7B选用Q5_1,而13B选择Q5_0
- 机器资源够用且对速度要求不是那么苛刻的情况下可以使用q8_0,接近F16模型的效果
- 需要注意的是F16以及q8_0并不会因为增加线程数而提高太多速度
- 线程数
-t与物理核心数一致时速度最快,超过之后速度反而变慢(M1 Max上从8改到10之后耗时变为3倍)
7B
| F16 | Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | |
| PPL | 10.793 | 12.416 | 12.002 | 11.155 | 10.905 | 10.79 |
| Size | 13.77G | 4.31G | 5.17G | 4.74G | 5.17G | 7.75G |
| ms/tok @ -t 2 | 144 | 87 | 88 | 143 | 157 | 103 |
| ms/tok @ -t 4 | 123 | 50 | 52 | 75 | 82 | 72 |
| ms/tok @ -t 8 | 126 | 41 | 49 | 46 | 49 | 69 |
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9854