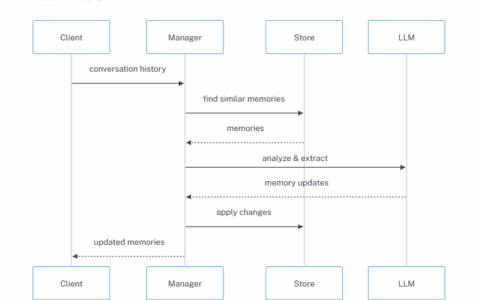
我们尝试将长期记忆与LLM结合使用。
在LangMem中,长期记忆的实现模式定义了以下两种:
- LangMem Doc – Hot Path(Conscious Formation) 一种在每次对话时实时更新长期记忆的方法。适用于要求即时记忆反映的场景。
- LangMem Doc – Background(Subconcious Formation) 另一种是在经过一定时间后以异步方式更新记忆的方法。适用于高效处理和存储大量信息的场景。
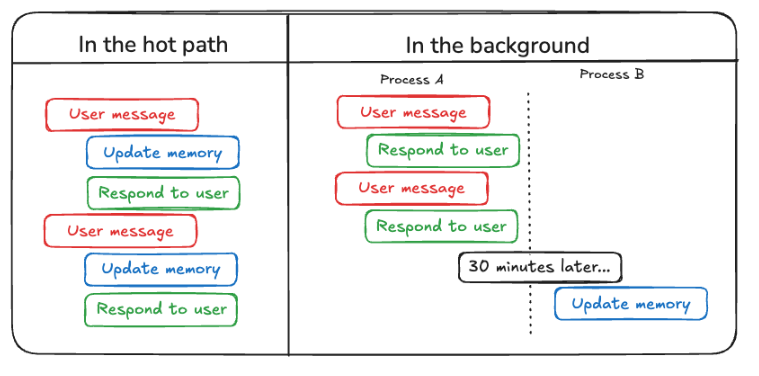
这里我们将实现Hot Path模式,尝试利用长期记忆进行对话。

关键点如下:
- 搜索长期记忆 从存储(store.search)中获取与用户关联的长期记忆
- 在系统消息中添加长期记忆 预先嵌入记忆信息,使LLM可参考
- 将对话内容反映至长期记忆 将用户的发言与LLM的回应添加到记忆中(manager.invoke)。
全部源代码
import os
import f_common
from langchain.chat_models import init_chat_model
from langgraph.func import entrypoint
from langgraph.store.memory import InMemoryStore
from pydantic import BaseModel, Field, conint
from langmem import create_memory_store_manager
#关键点如下:
# 搜索长期记忆
# 从存储(store.search)中获取与用户关联的长期记忆
# 在系统消息中添加长期记忆
# 预先嵌入记忆信息,使LLM可参考
# 将对话内容反映至长期记忆
# 将用户的发言与LLM的回应添加到记忆中(manager.invoke)
class UserFoodPreference(BaseModel):
"""用户饮食偏好的详细信息"""food_name: str = Field(..., description="菜名")
cuisine: str | None = Field(
None, description="料理类型(和食、洋食、中餐等)"
)
preference: conint(ge=0, le=100) | None = Field(
None, description="喜好程度(以0~100的分数表示)")
description: str | None = Field(
None, description="其他补充说明(例如,特定的调味或配料等)"
)
# 生成 LangGraph 内存存储 (BaseStore)
store = InMemoryStore(
index={
"dims": 1536,
# "embed": "openai:text-embedding-3-small", # 用于向量化的模型
"embed": "ollama:bge-m3",
}
)
manager = create_memory_store_manager(
#"anthropic:claude-3-7-sonnet-latest",
f_common.my_grok_llm,
namespace=("chat", "{user_id}"),
schemas=[UserFoodPreference],
instructions = "请详细抽取用户的偏好",
enable_inserts=True,
enable_deletes=False,
)
#llm = init_chat_model("anthropic:claude-3-7-sonnet-latest")
llm=f_common.my_grok_llm
@entrypoint(store=store)
def app(params: dict):
messages = params["messages"]
user_id = params["user_id"]
# 1. 从存储中搜索对应用户的长期记忆
memories = store.search(("chat", user_id))
# 2. 将长期记忆设定为系统消息
system_msg = f"""You are a helpful assistant.
## Memories
<memories>
{memories}
</memories>
"""
response = llm.invoke([
{
"role": "system",
"content": system_msg,
}, *messages
])
# 3. 将对话内容反映至长期记忆
manager.invoke({"messages": messages + [response]}, config={"configurable": {"user_id": user_id}})
return response.content
# ---- 更新长期记忆 ----
conversation = [
{"role": "user", "content": "我非常喜欢酱油拉面!!"},
]
app.invoke({"messages": conversation, "user_id": "MZ0001"})
# ---- 参考长期记忆 ----
conversation = [
{"role": "user", "content": "今天的午餐该吃什么呢?"},
]
message = app.invoke({"messages": conversation, "user_id": "MZ0001"})
print("### LLM:n", message)
memories = store.search(("chat", "MZ0001"))
print("### Memories:n", [m for m in memories])我们的输出

看上去好像没有任何记忆系统的作用
官方的输出

Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9709