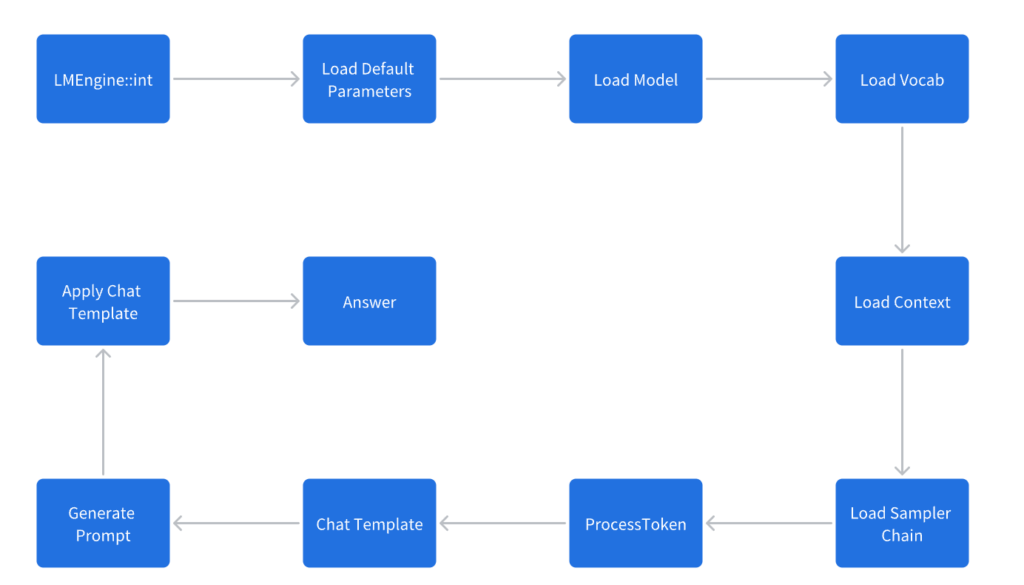
为了完成一个最精简的Chat的流程。
总体架构图
相关代码
int LM::SimpleChat(std::string model_path,std::string question,std::string & answer)
{
LMEngine* mEngine=this->Init(model_path);
llama_model * model=mEngine->model;
llama_context *ctx=mEngine->context;
const llama_vocab *vocab=mEngine->vocab;
llama_sampler * smpl=mEngine->sampler;
// helper function to evaluate a prompt and generate a response
auto generate = [&](const std::string & prompt) {
std::string response;
const bool is_first = llama_memory_seq_pos_max(llama_get_memory(ctx), 0) == -1;
// tokenize the prompt
const int n_prompt_tokens = -llama_tokenize(vocab, prompt.c_str(), prompt.size(), NULL, 0, is_first, true);
std::vector<llama_token> prompt_tokens(n_prompt_tokens);
if (llama_tokenize(vocab, prompt.c_str(), prompt.size(), prompt_tokens.data(), prompt_tokens.size(), is_first, true) < 0) {
GGML_ABORT("failed to tokenize the prompt\n");
}
// prepare a batch for the prompt
llama_batch batch = llama_batch_get_one(prompt_tokens.data(), prompt_tokens.size());
llama_token new_token_id;
while (true) {
// check if we have enough space in the context to evaluate this batch
int n_ctx = llama_n_ctx(ctx);
int n_ctx_used = llama_memory_seq_pos_max(llama_get_memory(ctx), 0) + 1;
if (n_ctx_used + batch.n_tokens > n_ctx) {
printf("\033[0m\n");
fprintf(stderr, "context size exceeded\n");
exit(0);
}
int ret = llama_decode(ctx, batch);
if (ret != 0) {
GGML_ABORT("failed to decode, ret = %d\n", ret);
}
// sample the next token
new_token_id = llama_sampler_sample(smpl, ctx, -1);
// is it an end of generation?
if (llama_vocab_is_eog(vocab, new_token_id)) {
break;
}
// convert the token to a string, print it and add it to the response
char buf[256];
int n = llama_token_to_piece(vocab, new_token_id, buf, sizeof(buf), 0, true);
if (n < 0) {
GGML_ABORT("failed to convert token to piece\n");
}
std::string piece(buf, n);
printf("%s", piece.c_str());
fflush(stdout);
response += piece;
// prepare the next batch with the sampled token
batch = llama_batch_get_one(&new_token_id, 1);
}
return response;
};
std::vector<llama_chat_message> messages;
std::vector<char> formatted(llama_n_ctx(ctx));
int prev_len = 0;
const char * tmpl = llama_model_chat_template(model, /* name */ nullptr);
messages.push_back({"user", strdup(question.c_str())});
int new_len = llama_chat_apply_template(tmpl, messages.data(), messages.size(), true, formatted.data(), formatted.size());
if (new_len > (int)formatted.size()) {
formatted.resize(new_len);
new_len = llama_chat_apply_template(tmpl, messages.data(), messages.size(), true, formatted.data(), formatted.size());
}
if (new_len < 0) {
fprintf(stderr, "failed to apply the chat template\n");
return 1;
}
// remove previous messages to obtain the prompt to generate the response
std::string prompt(formatted.begin() + prev_len, formatted.begin() + new_len);
// generate a response
printf("\033[33m");
std::string response = generate(prompt);
// 直接赋值,std::string 会进行深拷贝
answer=response;
printf("\n\033[0m");
// add the response to the messages
messages.push_back({"assistant", strdup(response.c_str())});
prev_len = llama_chat_apply_template(tmpl, messages.data(), messages.size(), false, nullptr, 0);
if (prev_len < 0) {
fprintf(stderr, "failed to apply the chat template\n");
return 1;
}
// free resources
for (auto & msg : messages) {
free(const_cast<char *>(msg.content));
}
return 1;
}首先 选用模型
测试环节,为提升性能,我们选用一个可能是目前最小的135Mb的模型
我们将SmolLM2在这里使用由 HuggingFace 创建并于近期(2024 年 11 月 1 日)发布的模型系列。我选择这个模型的原因是它的尺寸——顾名思义,它很小。该系列中最大的模型有 17 亿个参数,这意味着它需要大约 4GB 的系统内存才能以原始、未量化的形式(不包括上下文)运行!此外,还有 360M 和 135M 的版本,它们更小,应该可以轻松在 Raspberry Pi 或智能手机上运行。
下载地址:https://huggingface.co/collections/HuggingFaceTB/smollm2-6723884218bcda64b34d7db9
剩余内容需解锁后查看
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9990