PostgreSQL 是一款功能强大的开源对象关系数据库系统,它已将其功能扩展到传统数据管理之外,通过 pgvector 扩展支持矢量数据。这一新增功能满足了对高效处理高维矢量数据日益增长的需求,这些数据通常用于机器学习、自然语言处理 (NLP) 和推荐系统等应用。

什么是 pgvector?
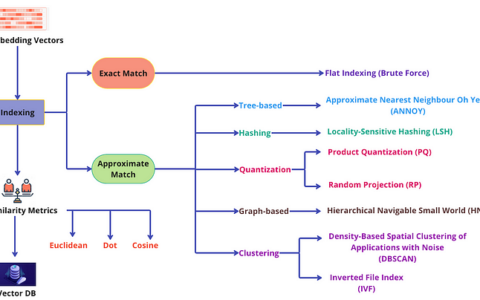
Pgvector 是 PostgreSQL 的一个扩展,允许它高效地存储和查询矢量数据。它引入了一种新的数据类型,vector旨在保存高维数据。此扩展使 PostgreSQL 能够执行矢量相似性搜索,使其适用于涉及机器学习模型、NLP 等的应用程序。
pgvector 的主要特点
- 向量数据存储
vector:您可以使用pgvector 提供的数据类型将高维向量直接存储在 PostgreSQL 表中。 - 相似性搜索:Pgvector 支持使用余弦相似度和欧几里得距离等指标进行相似性搜索。这对于在数据集中查找相似项目(例如相似的图像、文档或产品)至关重要。
- 与 SQL 集成:Pgvector 与 SQL 无缝集成,允许将向量操作与传统关系数据查询相结合的复杂查询。
将 pgvector 与 Timescale 结合使用
Timescale 是基于 PostgreSQL 构建的用于时间序列数据的扩展,与 pgvector 结合,为在同一数据库系统中管理时间序列和矢量数据提供了强大的解决方案。以下是如何使用 pgvector 和 Timescale:
安装:首先,在您的 PostgreSQL 数据库中安装 TimescaleDB 和 pgvector 扩展。
使用矢量数据创建超表:创建时间尺度超表并添加一列类型vector来存储矢量数据。
CREATE TABLE sensor_data (
time TIMESTAMPTZ NOT NULL,
data VECTOR
);
SELECT create_hypertable('sensor_data', 'time');
ALTER TABLE sensor_data ADD COLUMN data VECTOR;
索引和查询优化:为了提高查询性能,尤其是相似性搜索,请vector使用 pgvector 的索引功能在列上创建索引。
-- Similarity search
SELECT * FROM sensor_data WHERE data @@ '1,2,3'::vector;
-- Aggregation and grouping
SELECT time_bucket('1 day', time) AS day, avg(data) AS avg_data
FROM sensor_data GROUP BY day ORDER BY day;
-- Filtering and selection
SELECT * FROM sensor_data WHERE time >= '2023-06-02 00:00:00' AND time < '2023-06-03 00:00:00';
Pgvector 将 PostgreSQL 转变为一个多功能数据库系统,能够高效处理矢量数据,使其适用于从机器学习到 NLP 的广泛应用。与 Timescale 结合使用时,它提供了一个强大的平台,可在同一生态系统中管理时间序列和矢量数据,简化工作流程并实现更复杂的数据分析。
PostgreSQL 与 pgvector 的优点和缺点
优势
- SQL 支持: PostgreSQL 借助 pgvector 扩展,可在同一数据库中高效处理结构化数据和矢量数据。此集成可实现复杂的过滤搜索、SQL 和矢量联合查询,充分利用这两种数据类型强大且广泛使用的 SQL 语言。
- 成熟的生态系统:通过扩展 PostgreSQL 以支持向量搜索,用户可以从通用数据库的成熟工具、集成和社区支持中受益。这减少了对专业技能的额外劳动力成本和专业数据库的许可成本。
- 成本效益:与专用矢量数据库和其他集成矢量数据库相比,带有 pgvector 的 PostgreSQL 为管理 AI/LLM 相关数据提供了一种经济高效的解决方案。尽管成本较低,但它在各种过滤比率下都能提供高搜索准确度和吞吐量,因此对于运行大量矢量搜索的企业来说,这是一个经济实惠的选择。
- 灵活性:通过高效处理矢量数据,带有 pgvector 的 PostgreSQL 支持从机器学习到自然语言处理的广泛应用。它适用于各种用例,包括相似性搜索,这对于在大型数据集中查找相似的图像、文档或产品至关重要。
弱点
- 性能和索引构建时间:与领先的集成向量数据库 MyScale 相比,PostgreSQL 与 pgvector 在过滤向量搜索性能和索引构建时间方面存在局限性。MyScale 在搜索准确度、吞吐量和构建向量索引所需的时间方面明显优于 PostgreSQL 与 pgvector,使其成为需要高速向量搜索的应用程序的更高效选择。
- 后过滤精度问题:带有 pgvector 的 PostgreSQL 在过滤向量搜索方法中使用了后过滤。这种方法已证明会导致某些查询的精度较低(低于 50%),导致搜索结果在实际情况下几乎无法使用。这种限制可能会阻碍带有 pgvector 的 PostgreSQL 在依赖高精度过滤向量搜索的实际应用中的有效性。
- 可扩展性问题:尽管 PostgreSQL 以处理结构化数据的可扩展性而闻名,但在管理大规模矢量数据时,pgvector 的性能可能不如某些专用矢量数据库那样高效。这可能会给需要处理数百万个高维矢量的应用程序带来挑战。
PostgreSQL 增加了 pgvector 扩展,为希望在单个数据库系统中管理结构化数据和矢量数据的组织提供了一个极具吸引力的选择。它与 SQL 的集成、成本效益以及成熟生态系统的支持使其成为广泛应用的理想选择。然而,当涉及到高速、高精度过滤矢量搜索以及处理海量矢量数据集的可扩展性时,专用矢量数据库或更优化的集成矢量数据库(如 MyScale ( https://myscale.com/ ) )可能会提供卓越的性能和效率。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/4084