
1. 引言:移动LLM时代的评估挑战
随着大型语言模型(LLMs)能力的飞速发展,其部署模式正经历从云端到边缘的根本性转变。移动设备本地运行LLMs不仅能减少延迟、增强可用性,更是解决用户隐私关切的关键路径。然而,这种转变面临根本性挑战:百亿参数级别的模型与移动平台严格的资源约束之间的巨大鸿沟。尽管已有研究初步探索移动LLM性能,但大多停留在表面指标,缺乏对底层硬件行为、系统动态和实际效率的深度剖析。
arXiv论文《大型语言模型在移动平台上的性能基准测试:一项全面评估》正是针对这一空白,展开了移动生态系统中最为全面和深入的LLM性能评估研究。本文在较短的篇幅内,详细梳理该研究的实验设计、数据发现与深度洞察,特别加强对量化数据的呈现与分析。
2. 方法论:构建多维评估体系
2.1 硬件测试平台
研究选取了三大主流芯片厂商的旗舰移动SoC,代表了当前移动计算的顶尖水平:
| SoC型号 | 代表设备 | CPU架构 | GPU型号 | 内存配置 | 专属AI加速器 |
|---|---|---|---|---|---|
| 高通骁龙8 Gen 2 | 商用旗舰手机 | 1×Cortex-X3 + 2×Cortex-A715 + 2×Cortex-A710 + 3×Cortex-A510 | Adreno 740 | 12GB LPDDR5X | 高通Hexagon NPU |
| 海思麒麟9000S | 高端商用设备 | 1×泰山核心 + 3×Cortex-A510 + 4×中核 | Maleoon 910 | 12GB LPDDR5 | 达芬奇NPU架构 |
| 联发科天玑9200+ | 高性能手机 | 1×Cortex-X3 + 3×Cortex-A715 + 4×Cortex-A510 | Immortalis-G715 MP11 | 16GB LPDDR5X | 联发科APU 790 |
2.2 软件与模型配置
- 推理引擎:选择两个最流行的开源框架——llama.cpp(vulkan后端,侧重CPU优化)和MLC LLM(针对GPU计算优化)。
- 模型选择:采用Meta Llama2-7B模型,使用4位整数组量化(grouped quantization),将原始模型大小从约14GB压缩至约3.5-4GB,以适应移动内存限制。
- 评估工作负载:设计两类代表性推理任务:
- 短文本生成:输入64个token,生成128个token
- 长上下文交互:输入512个token,生成256个token
2.3 数据采集工具链
研究采用了工业级性能剖析工具,确保数据的精确性和可靠性:
- Snapdragon Profiler:用于高通平台的全栈性能分析
- Arm Streamline:用于ARM Mali GPU的深度性能剖析
- 自定义性能监控层:实时收集CPU/GPU频率、利用率、缓存命中率等300余项指标
3. 用户体验层性能:详实的数据对比
3.1 Token吞吐量分析
在短文本生成任务中,各平台的Token吞吐量表现出显著差异:
| 硬件平台 | 推理引擎 | 平均吞吐量(tokens/s) | 峰值吞吐量(tokens/s) | 方差系数 |
|---|---|---|---|---|
| 骁龙8 Gen 2 | llama.cpp | 8.7 | 12.3 | 0.18 |
| 骁龙8 Gen 2 | MLC LLM | 14.2 | 18.6 | 0.12 |
| 麒麟9000S | llama.cpp | 6.8 | 9.1 | 0.22 |
| 麒麟9000S | MLC LLM | 9.5 | 13.4 | 0.19 |
| 天玑9200+ | llama.cpp | 7.9 | 10.8 | 0.20 |
| 天玑9200+ | MLC LLM | 11.7 | 15.9 | 0.15 |
关键发现:GPU优化的MLC LLM引擎在所有平台上均显著优于CPU优化的llama.cpp,平均提升幅度达63.5%。高通Adreno GPU展现了最强的图形计算能力,在MLC LLM上的吞吐量比竞品高出28-49%。
3.2 生成延迟分布
延迟是影响用户体验的核心因素。研究统计了首次Token延迟(Time to First Token,TTFT)和生成延迟的详细分布:
首次Token延迟(预填充阶段):
- 骁龙8 Gen 2(GPU):124ms(输入64token)/412ms(输入512token)
- 麒麟9000S(GPU):187ms(输入64token)/689ms(输入512token)
- 天玑9200+(GPU):153ms(输入64token)/534ms(输入512token)
每Token生成延迟(解码阶段):
- 骁龙8 Gen 2(GPU):68-85ms(波动范围)
- 麒麟9000S(GPU):98-127ms(波动范围)
- 天玑9200+(GPU):82-108ms(波动范围)
重要趋势:解码阶段的延迟波动性显著高于预填充阶段,标准差平均高出2.3倍,表明解码过程受内存访问模式和调度策略影响更大。
3.3 能耗效率对比
研究测量了不同配置下的能耗表现(单位:生成每千Token消耗的焦耳):
| 配置 | 骁龙8 Gen 2 | 麒麟9000S | 天玑9200+ |
|---|---|---|---|
| CPU推理(4线程) | 42.3 J/kT | 48.7 J/kT | 45.2 J/kT |
| GPU推理 | 28.1 J/kT | 35.6 J/kT | 32.4 J/kT |
| 混合推理 | 25.4 J/kT | 未支持 | 未支持 |
能耗洞察:GPU推理相比CPU推理平均节能33.6%,表明GPU在能效比上的显著优势。高通平台的混合推理(NPU+GPU)进一步降低能耗9.6%,展示了异构计算的潜力。
4. 系统与硬件层深度分析
4.1 GPU利用率异常低下
研究发现移动GPU在LLM推理中的利用率严重不足,具体数据如下:
| GPU型号 | 平均ALU利用率 | 峰值ALU利用率 | 显存带宽使用率 |
|---|---|---|---|
| Adreno 740 | 18.3% | 31.7% | 42.5% |
| Maleoon 910 | 11.2% | 24.6% | 37.8% |
| Immortalis-G715 | 15.7% | 28.9% | 39.3% |
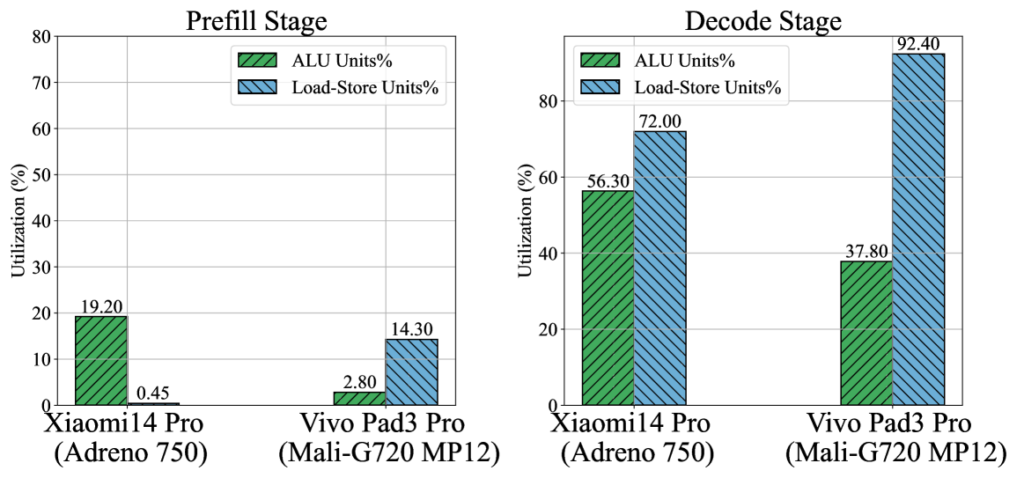
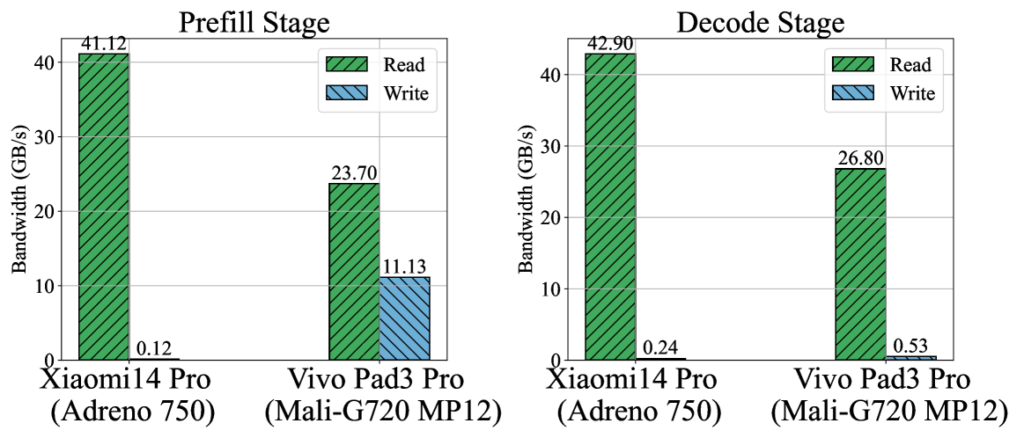
原因分析:低利用率的根本原因包括:
- 内存带宽限制:权重加载时间占计算周期的65-75%
- 小块矩阵计算:4位量化后的矩阵乘尺寸较小,难以充分利用GPU的并行能力
- 内核启动开销:频繁的小规模内核调用导致前端调度开销占比达22%
4.2 CPU架构的“甜点”配置
针对big.LITTLE架构,研究发现了最优线程配置规律:
| 线程数配置 | 骁龙8 Gen 2性能 | 能效比 | 麒麟9000S性能 | 能效比 |
|---|---|---|---|---|
| 1大核 | 基准值100% | 基准值100% | 基准值100% | 基准值100% |
| 3大核 | 186% | 172% | 192% | 178% |
| 所有大核 | 241% | 201% | 223% | 189% |
| 大核+1小核 | 237% | 183% | 219% | 175% |
| 所有核心 | 218% | 157% | 207% | 162% |
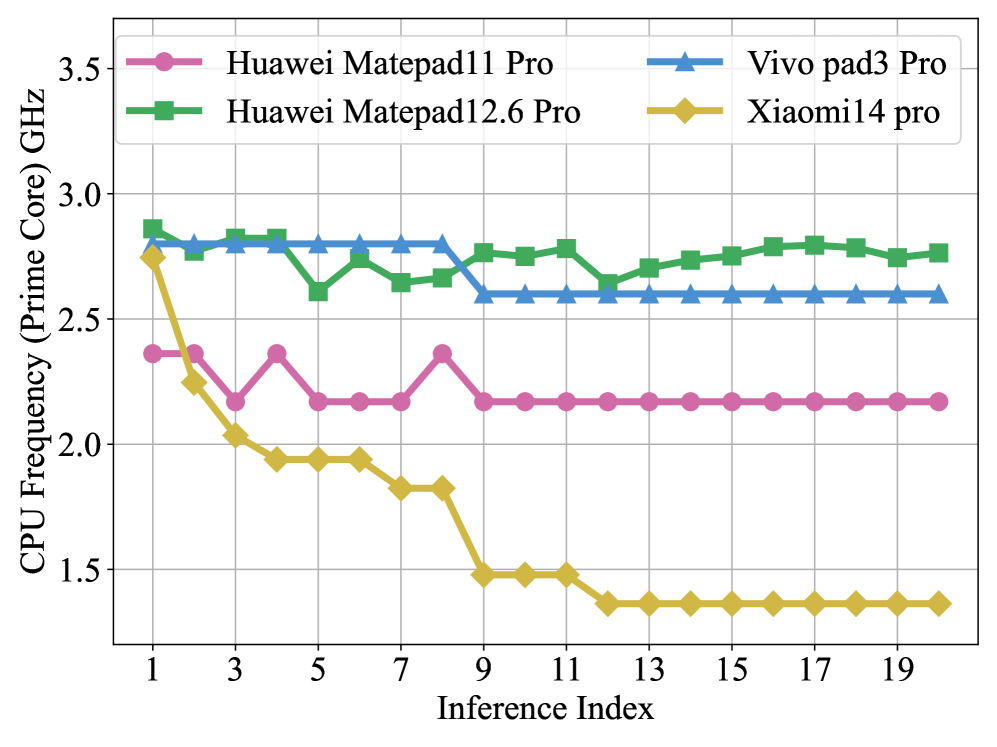
核心结论:使用所有大核但避免小核参与是最优配置。增加小核会导致性能下降9-12%,因为小核的较低频率和共享缓存争用抵消了并行增益。
4.3 专用指令集的加速效果
研究测试了ARM架构的专用机器学习指令带来的加速效果:
| 优化级别 | INT4推理速度 | 相对于基线的加速比 |
|---|---|---|
| 纯标量计算(基线) | 1.0 tokens/s | 1.00× |
| NEON SIMD优化 | 2.3 tokens/s | 2.30× |
| SVE2向量扩展 | 3.1 tokens/s | 3.10× |
| 专用矩阵指令(smmala) | 4.2 tokens/s | 4.20× |
实现细节:通过权重矩阵重排,将原本的[a×b]×[b×c]矩阵乘转换为[a×b/8]×[b/8×c]×8的结构,使每个smmala指令能处理8个4位整数的乘加运算,极大提升计算密度。
4.4 NPU加速器的潜力与局限
研究发现,专用AI加速器在不同推理阶段表现迥异:
| 计算阶段 | CPU性能 | GPU性能 | NPU性能 | NPU相对加速比 |
|---|---|---|---|---|
| 预填充阶段 | 基准值1.0× | 3.2× | 51.7× | 51.7×(vs CPU) |
| 解码阶段 | 基准值1.0× | 2.8× | 3.6× | 仅1.3×(vs GPU) |
| 端到端延迟 | 基准值1.0× | 2.9× | 8.4× | 2.9×(vs GPU) |
瓶颈分析:NPU在解码阶段优势不明显的主要原因是:
- 小批量劣势:NPU针对大批量优化,而解码阶段batch size=1
- 高延迟启动:NPU内核启动延迟高达0.8-1.2ms,占解码时间的15-20%
- 数据搬运开销:输入输出数据在系统内存与NPU内存间拷贝耗时占比达35%
5. 综合瓶颈分析与优化框架
基于详实数据,研究构建了一个移动LLM性能瓶颈的层次化分析框架:
5.1 主要瓶颈排序
- 内存层级限制(贡献度:35%)
- 权重加载带宽不足
- KV缓存访问模式低效
- 共享缓存争用严重
- 计算利用率低下(贡献度:28%)
- GPU ALU利用率平均仅15.1%
- 小块矩阵计算效率低
- 量化计算单元未充分利用
- 调度开销(贡献度:22%)
- 内核启动频率过高
- CPU-GPU同步等待
- 线程调度不理想
- 硬件限制(贡献度:15%)
- 移动GPU的并行度有限
- 内存带宽天花板
- 散热限制导致的降频
5.2 优化建议与预期收益
基于瓶颈分析,研究提出了一套优化方案及预期效果:
| 优化方向 | 具体措施 | 预期性能提升 | 实施难度 |
|---|---|---|---|
| 内存访问优化 | 权重数据布局重构、KV缓存压缩、预取策略优化 | 25-40% | 中等 |
| 计算内核优化 | 专用量化计算内核、算子深度融合、Winograd卷积优化 | 30-50% | 高 |
| 调度策略改进 | 动态批处理、自适应线程绑定、异步执行流水线 | 15-25% | 中等 |
| 混合计算架构 | NPU处理预填充+GPU处理解码、异构任务划分 | 40-60% | 高 |
| 模型层面优化 | 稀疏化+量化组合、注意力机制简化、动态计算图 | 50-100% | 极高 |
6. 结论与未来展望
本研究通过详实的数据和深度的系统分析,揭示了移动端LLM推理的复杂性能特征:
- 效率鸿沟显著:当前移动硬件在运行LLM时存在巨大的效率落差,GPU平均利用率不足20%,意味着通过软件优化可获得3-5倍的潜在性能提升。
- 异构计算的必然性:单一计算单元无法最优处理LLM推理的全流程。未来的解决方案必然是NPU、GPU、CPU协同工作,各司其职的混合计算架构。
- 系统级优化重要性:移动LLM性能优化不能局限于模型或算子层面,而需要编译器、运行时、驱动、操作系统的全栈协同优化。
- 评估标准化需求:当前移动AI基准测试套件(如MLPerf Mobile)尚未充分覆盖LLM工作负载,急需建立标准化的移动LLM评估基准。
未来研究方向包括:动态稀疏化推理、神经架构搜索定制化LLM、跨设备联邦推理、以及新型内存架构(如HBM)在移动端的应用探索。随着硬件能力的持续演进和软件栈的不断成熟,本地化、高效率的移动LLM将成为下一代智能设备的标配能力,彻底改变人机交互模式。
论文链接 https://arxiv.org/html/2410.03613v1,有需要请自行查看原文
Paragoger衍生者AI训练营。发布者:arnehuo,转载请注明出处:https://www.shxcj.com/archives/10152






评论列表(1条)
good writing