摘要
微软QLIB(Quantitative LIBrary)是一个由微软研究院(Microsoft Research)开发的开源AI导向量化投资平台,旨在利用人工智能技术赋能量化研究,从idea探索到生产部署的全链路实现。该平台支持监督学习、市场动态建模和强化学习等多种机器学习范式,涵盖数据处理、模型训练、回测、风险建模、投资组合优化和订单执行等完整量化投资流程。本报告将全面剖析QLIB的基本功能、常用API、具体功能模块、扩展能力、接口集成以及基于其构建的产品。通过详细的代码示例、案例分析和与其他量化库的比较,揭示QLIB在量化金融领域的优势与潜力。
引言
1.1 QLIB的背景与发展历史
量化投资(Quantitative Investing)作为金融科技领域的核心分支,已从传统的统计模型演变为高度依赖人工智能的智能决策系统。然而,现有工具往往在数据处理、模型集成和生产部署上存在碎片化问题,无法高效桥接AI技术与实际投资实践。为解决这一痛点,微软研究院于2020年9月正式发布QLIB平台。QLIB的全称为“Quantitative LIBrary”,其设计理念源于微软在AI for Finance领域的长期积累,旨在“实现AI技术的潜力、赋能研究并创造量化投资的价值”。
QLIB的起源可追溯到微软内部的AI金融研究项目。早在2018年,微软就开始探索深度学习在股票预测中的应用,并于2020年通过arXiv论文《Qlib: An AI-oriented Quantitative Investment Platform》正式开源。
主要的模块内容
1.2 QLIB的核心目标与价值
QLIB的目标是降低量化投资的门槛,让用户从零开始构建端到端AI管道。其价值体现在三个层面:一是高效性,通过模块化设计加速从数据到策略的迭代;二是灵活性,支持自定义扩展以适应不同市场(如美股、A股);三是可生产化,提供在线部署和风险控制工具,确保研究成果落地。
在当前AI浪潮下,QLIB填补了传统量化工具(如Backtrader)的AI空白,帮助用户应对市场动态变化。例如,在高频交易中,QLIB的强化学习模块可优化订单执行,减少滑点损失。总体而言,QLIB不仅是工具,更是量化金融AI化的催化剂。
1.3 和其余库的比较
| 库名称 | 核心功能 | AI支持 | 扩展性 | 性能 | 适用场景 |
| QLIB | 全链路(数据-模型-回测) | 强(SL/MDM/RL) | 高(自定义模块) | 优秀(DataServer) | AI量化研究、生产 |
| Backtrader | 回测/策略 | 弱(无内置ML) | 中(插件) | 中等 | 简单策略测试 |
| Zipline | 回测/事件驱动 | 中(集成Scikit) | 高(Pythonic) | 好(US数据) | 美股算法交易 |
| QuantConnect | 云回测/实时 | 中(LEAN引擎) | 中(社区算法) | 优秀(云) | 初学者/多资产 |
QLIB在AI深度上胜出,但Backtrader更轻量。共识:QLIB适合高级用户,Zipline适合初学。
基本功能
2.1 整体框架概述
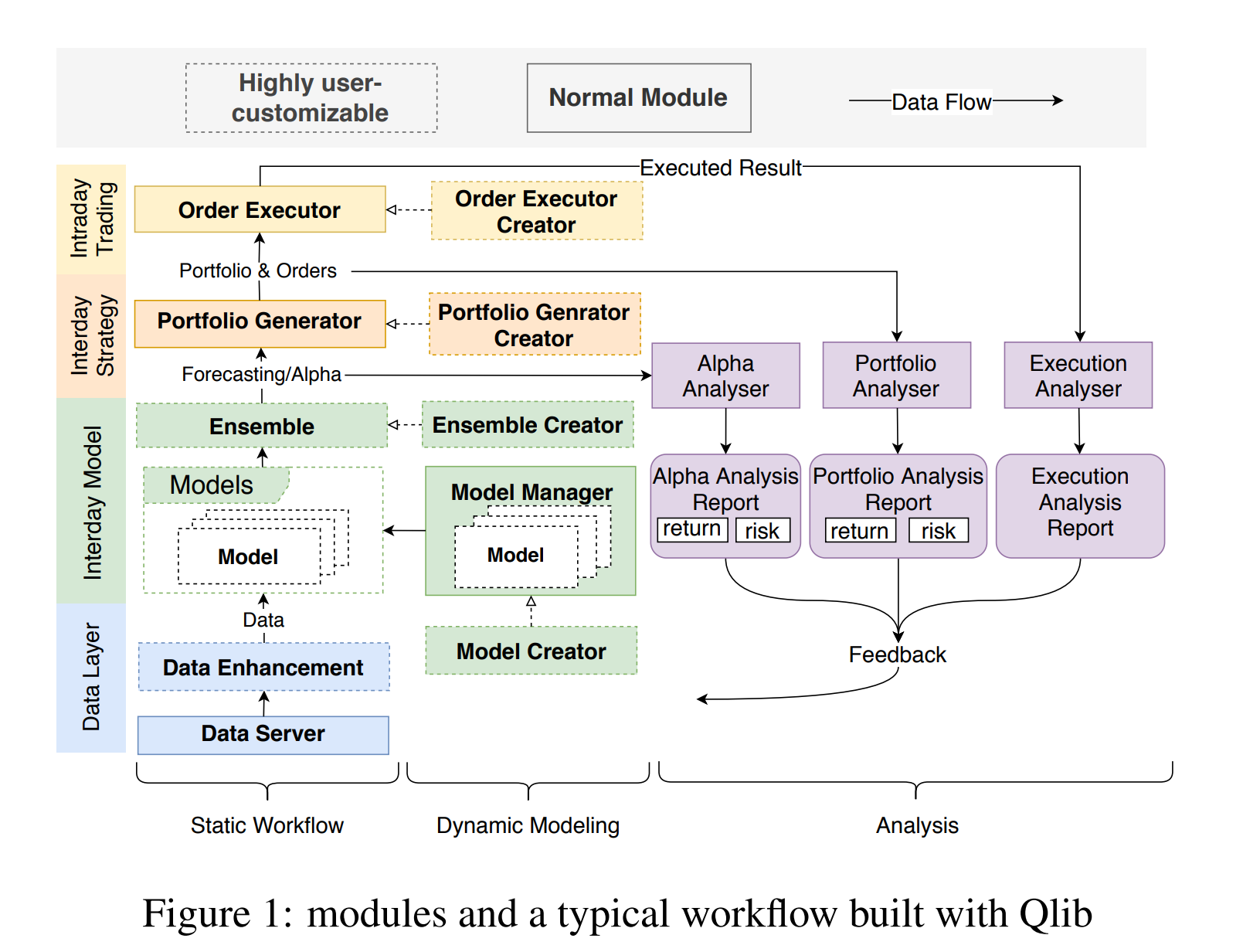
QLIB采用分层架构,包括基础设施层、核心组件层和工作流层。基础设施层提供数据服务器(DataServer),支持高性能数据管理和检索,基准测试显示其在单CPU环境下处理速度比HDF5快25倍(7.4s vs 184.4s)。核心组件层涵盖数据处理、模型训练、策略生成和回测;工作流层通过YAML配置文件或Python代码自动化整个管道。
基本功能可概括为“全链路量化投资支持”:从Alpha因子挖掘(alpha seeking)到风险建模(risk modeling)、投资组合优化(portfolio optimization)和订单执行(order execution)。QLIB内置Alpha158和Alpha360数据集,覆盖美股和中股市值因子,支持监督学习(如LightGBM)和强化学习(如PPO)。
2.2 数据处理基础
QLIB的核心是高效数据管道。用户可通过内置处理器加载历史数据,支持CSV、HDF5和自定义格式。基本功能包括时间序列对齐、缺失值填充和特征工程,确保数据一致性。
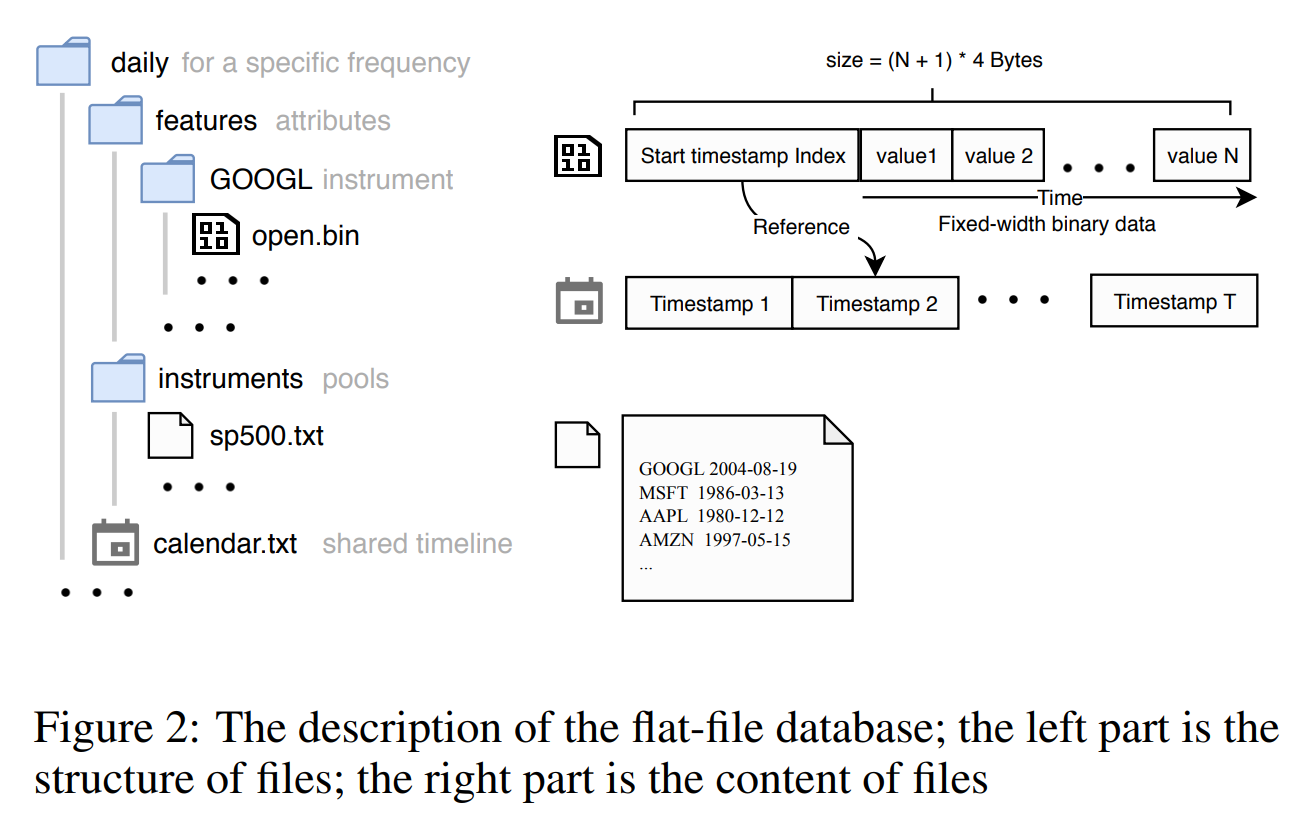
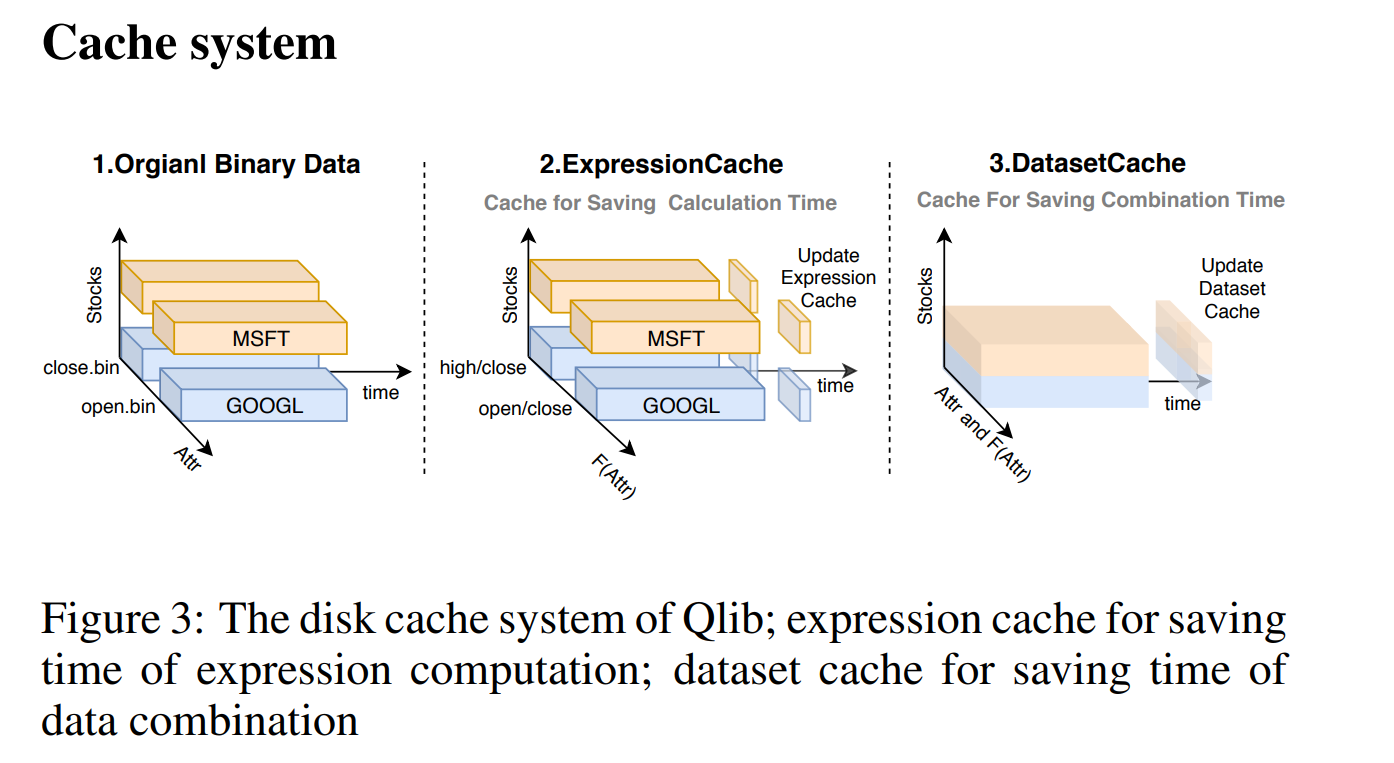
2.3 模型训练与预测
QLIB集成多种ML模型,如LightGBM、TabNet和Transformer,支持批量训练和超参数调优。基本预测功能输出股票回报率或因子分数。
2.3.1 模型训练的主要用途
模型训练是QLIB中Forecast Model(预测模型)模块的核心功能,它通过机器学习算法从历史金融数据中学习模式,生成可操作的投资信号。简单来说,模型训练不是孤立的“训练模型”,而是嵌入量化投资管道,用于预测未来资产回报、识别超额收益机会(alpha seeking),最终指导买卖决策。
核心用途
- Alpha预测与股票选股:模型的主要输出是每个股票的“预测分数”(prediction score),分数越高,表示该股票未来预期盈利潜力越大。这分数可直接用于Top-K选股策略,例如选出分数前50名的股票构建多头组合(long-only)或多空组合(long-short)。在量化金融中,这帮助投资者捕捉市场非线性模式,避免主观判断。
- 市场动态建模:通过监督学习(supervised learning)、市场动态建模(market dynamics modeling)和强化学习(reinforcement learning)等范式,模型适应市场变化。例如,监督学习挖掘历史数据中的复杂模式;强化学习优化连续交易决策,如订单执行路径,减少滑点(slippage)和交易成本。
- 风险与组合优化:训练后的模型可与风险模型结合,计算边际风险贡献,支持均值-方差优化(mean-variance optimization)或CVaR(条件价值-at-风险)优化,构建低风险、高回报的投资组合。
- 自动化R&D:集成RD-Agent(微软的LLM代理)后,模型训练可自动化,包括因子筛选和超参数调优,实现从idea到生产的闭环。
2.3.2 因子的作用
因子(factors)是QLIB数据层(Data Layer)的核心,指从原始金融数据(如OHLCV:开高低收成交量)工程化生成的特征信号。报告中提到的Alpha158和Alpha360是典型示例,它们不是简单指标,而是精心设计的预测因子库,用于捕捉股票的超额回报(alpha)。因子的本质是“alpha seeking”的工具,帮助模型识别市场无效性。
2.1 核心用途
- 特征工程与Alpha挖掘:因子作为模型的输入特征,提供多维度信号(如动量、价值、波动率)。例如,Alpha158包含158个因子,覆盖技术指标(RSI、MA)和横截面统计,帮助模型从噪声中提取alpha信号,实现“因子-模型共优化”。
- 支持多范式建模:在监督学习中,因子是X(输入);在强化学习中,作为状态空间的一部分,辅助决策。它们桥接原始数据与高级模型,减少手动工程负担。
- 策略生成与回测:因子分数可直接生成信号,或经模型增强后用于TopkDropout策略(选Top-K股票,动态掉落低质因子)。这在量化投资中用于构建因子组合,避免单一因子衰退。
- 数据中心化R&D:通过RD-Agent(Q),因子可自动化筛选(pruning),使用70%更少因子实现2倍年化回报,适用于数据驱动的因子-模型联合开发。
2.4 回测与评估
内置回测引擎模拟真实交易环境,计算IC(Information Coefficient)、Sharpe比率等指标。基本功能支持多资产、多策略并行回测。
什么是IC
IC,全称为 Information Coefficient(信息系数),是量化投资和金融建模领域的一个核心评估指标。它主要用于衡量预测模型的预测准确性和有效性,特别是在股票选股、alpha因子挖掘和风险模型中。简单来说,IC 量化了模型输出的“预测分数”(prediction score)与实际市场回报(realized return)之间的线性相关程度。高 IC 值表示模型能更好地捕捉市场机会,低 IC 值则提示模型可能存在偏差或噪声。
IC 源于金融计量经济学,由 Grinold 和 Kahn 在其经典著作《Active Portfolio Management》(1999)中正式引入。它是量化策略评估的“金标准”之一,常与 ICIR(Information Coefficient Information Ratio,IC 的信息比率)结合使用。
IC 的定义与含义
- 核心含义:IC 反映了模型的“信息含量”,即预测信号中包含的有效信息比例。假设模型预测某股票未来回报率为 +5%,如果实际回报也接近 +5%,则贡献正 IC;反之则负相关。
- 取值范围:
- IC ∈ [-1, 1],类似于 Pearson 相关系数。
- 理想值:> 0.05(日频模型),表示模型有统计显著的预测力。
- IC = 0:无相关性(随机预测)。
- IC < 0:反向预测(模型失效)。
- 类型区分:
- 横截面 IC (Cross-Sectional IC):在单一时间点(e.g., 某交易日),跨多个资产(e.g., 500 只股票)的相关性。用于选股模型评估。
- 时间序列 IC (Time-Series IC):跨多个时间点(e.g., 252 个交易日),单一资产或组合的相关性。用于趋势预测模型。
- Rank IC (RIC):使用排名相关(Spearman 相关)而非绝对值,鲁棒性更强,减少极端值影响。
在实际应用中,IC 不是静态值,而是滚动计算(e.g., 滚动 20 日窗口),以捕捉模型的时变稳定性。如果 IC 持续衰减,可能表示因子“枯竭”或市场适应。
什么是Sharpe比率
Sharpe比率(Sharpe Ratio),也称为夏普比率,是金融投资领域的一个核心风险调整绩效指标。它由美国经济学家威廉·夏普(William Sharpe)于1966年提出,并在1990年因其在资本资产定价模型(CAPM)中的贡献获得诺贝尔经济学奖。Sharpe比率的主要目的是衡量投资组合或策略的超额回报相对于其风险的效率,帮助投资者比较不同资产或策略的表现,而不仅仅看绝对回报。简单来说,它回答了这样一个问题:为承担单位风险,我能获得多少额外回报?
Sharpe比率越高,表示该投资在风险调整后的表现越好(即“性价比”越高)。它广泛应用于量化投资、基金评估和风险管理中,例如在QLIB平台中,用于回测策略的绩效评测(如计算年化Sharpe以优化Alpha模型)。
- Sharpe比率的定义与含义
- 核心含义:Sharpe比率量化了投资的“风险回报比”。它不是简单回报率,而是扣除无风险利率后的超额回报,除以回报的标准差(波动率)。这反映了投资者为每单位风险(不确定性)所获得的补偿。
- 取值解读:
- Sharpe > 1:优秀(高效策略)。
- Sharpe 0.5-1:中等(可接受)。
- Sharpe < 0:糟糕(回报甚至低于无风险资产)。
- Sharpe = 0:无风险调整收益(回报等于无风险利率)。
- 类型区分:
- 年化Sharpe:最常用,按年调整(乘以√252,假设252个交易日)。
- 月化/日化:用于短期评估,但需注意频率转换。
- 扩展变体:如Sortino比率(仅考虑下行风险)或Calmar比率(用最大回撤代替标准差)。
在量化金融中,Sharpe比率是策略优化的“北极星”:例如,在市场波动大的2022年,美股策略的Sharpe可能降至0.8以下,提示需增加对冲。
回测(backtesting)通过历史数据重现交易过程,评估策略在过去市场的表现;评测(evaluation)则聚焦于性能指标计算、风险分析和可视化报告,帮助用户迭代优化。QLIB的设计强调模块化、可扩展性和生产化,支持从低频(日频)到高频(日内)场景。
2.4.1 回测(Backtesting)的具体实现
QLIB的回测模块位于qlib.backtest包下,采用**事件驱动(event-driven)和向量化(vectorized)**混合模式,支持多资产、多策略并行模拟。核心目标是模拟真实交易,包括交易成本、滑点(slippage)和流动性约束。回测不只是“历史模拟”,而是嵌入全链路:从预测分数(pred_score)生成信号,到执行订单、计算持仓变化。
关键组件
- Executor(执行器):核心引擎,负责时间推进、订单生成和持仓更新。支持BacktestExecutor(标准回测)和NestedExecutor(高频嵌套执行)。
- Strategy(策略):信号生成器,如TopkDropoutStrategy(Top-K选股+动态掉落),从pred_score产生买卖决策。
- Dataset/PredScore:输入数据,包括预测分数(Pandas Series格式,index为[instrument, datetime])。
- Report(报告):输出持仓、回报和交易日志,支持HTML/PDF导出。
- 交易成本模型:内置开仓/平仓佣金(open_cost/close_cost)、最小费用(min_cost)和滑点(slippage_model,如体积加权滑点)。
- 环境支持:集成PIT数据库,避免数据泄漏;高频模式下支持tick-by-tick模拟(GitHub Issue #18讨论)。
实现流程(Step-by-Step)
- 初始化环境:通过qlib.init()加载数据源(e.g., Alpha158数据集)。
- 生成预测分数:模型(如LightGBM)输出pred_score,表示股票预期回报。
- 策略决策:Strategy基于pred_score生成交易信号(e.g., 买入Top-50分数股票)。
- 执行模拟:Executor按时间步(日/分/秒)推进,处理订单、更新持仓,扣除成本。
- 输出报告:生成positions(持仓)、trades(交易记录)和performance(绩效)。
- 高频扩展:使用Nested Decision Execution Framework(v0.9+),日内订单可嵌套更细粒度执行(e.g., TWAP订单分割)。
回测支持多线程加速,基准测试显示在TB级数据下,处理速度比传统工具快3-5倍。2025年更新:增强RL集成(QlibRL),回测中直接优化执行路径。
2.4.2 评测(Evaluation)的具体实现
QLIB的评测模块位于qlib.contrib.report和qlib.contrib.evaluate下,聚焦风险调整绩效和可视化分析。它不是简单指标堆砌,而是与回测无缝集成:回测输出report后,直接传入评测函数计算指标。核心是累积回报求和(summation-based),避免指数化偏差(e.g., 复合回报不夸大长期曲线)。
2.1 关键组件
- Analysis(分析器):analysis_position(持仓分析)、analysis_model(模型评估)。
- Risk Analysis:计算因子暴露、VaR、MDD。
- Metrics(指标):IC(信息系数)、Sharpe比率、Turnover(换手率)、IR(信息比率)、MDD(最大回撤)。
- Report Generator:生成图表,如累计回报曲线、风险热图,支持HTML导出。
- Recorder:实验管理,跟踪多轮评测(类似MLflow)。
2.2 实现流程(Step-by-Step)
- 输入准备:从回测获取report(含positions、returns)。
- 指标计算:逐日/滚动窗口计算原始指标(e.g., 日回报)、成本调整后指标。
- 风险建模:使用因子模型(FRM)分解风险,计算边际贡献。
- 可视化:生成多图报告(e.g., IC衰减图)。
- 自动化:qrun后自动调用port_analysis_config,输出JSON/HTML。
常用API
QLIB的API设计简洁,基于面向对象范式。以下列出核心API,附代码示例(基于v0.9.8文档)。
3.1 初始化与配置API
- qlib.init(provider_uri=None, region=”us”):初始化QLIB环境,指定数据源和市场区域。 示例:
- Python
import qlibfrom qlib.config import REG_USqlib.init(provider_uri="~/.qlib/qlib_data/us_data", region=REG_US)- 此API加载数据目录,设置默认处理器。
- qrun(workflow_config):运行完整工作流,从YAML配置文件自动化管道。 示例(LightGBM基准):
- Bash
cd examplesqrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml- 输出包括模型预测、回测报告和可视化图表。
3.2 数据API
- D.calendar(start_time=None, end_time=None, freq=”day”):获取日历数据。 示例:
- Python
from qlib.data import Ddates = D.calendar(start_time="2020-01-01", end_time="2025-12-31")print(len(dates)) # 输出交易日数量- D.features(instruments, fields, start_time, end_time, freq=”day”):提取特征数据。 示例:
- Python
data = D.features(["AAPL"], ["$close", "Ref($close, 1)"], "2020-01-01", "2025-12-31")print(data.shape) # (时间步, 特征数)3.3 模型API
- Model.fit(train_data, valid_data):训练模型。 示例(LightGBM):
- Python
from qlib.contrib.model.gbdt import LGBModelmodel = LGBModel()model.fit(train_data, valid_data)pred = model.predict(test_data)- Predictor.predict(dataset):生成预测。 示例:
- Python
from qlib.workflow import Rwith R.get_recorder(experiment_name="test").start(experiment_name="prediction"): pred = recorder.load_object("pred")3.4 策略与回测API
- TopkDropoutStrategy.generate_trade_decision(pred_score):生成交易信号。 示例:
- Python
from qlib.contrib.strategy.strategy import TopkDropoutStrategystrategy = TopkDropoutStrategy(topk=50, n_drop=5)decision = strategy.generate_trade_decision(pred_score)- BacktestExecutor(pred_score, strategy, start_time, end_time):执行回测。 示例:
- Python
from qlib.backtest import BacktestExecutorexecutor = BacktestExecutor(pred_score, strategy, "2020-01-01", "2025-12-31")report = executor.execute()3.5 评估API
- risk_analysis(executor):风险分析。 示例:
- Python
from qlib.contrib.report import analysis_modelanalysis_model(pred_score, "risk_analysis_report.html")这些API覆盖80%常见用例,支持链式调用。高级用户可通过Recorder管理实验日志。
具体功能
4.1 数据管理模块
QLIB的数据模块是其基础设施的核心,支持多源数据集成。DataHandler负责特征工程,如计算移动平均(MA)、相对强度指数(RSI)和Alpha因子。
- 数据集构建:使用Alpha158(158个因子,美股)或自定义处理器。 示例代码:
- Python
from qlib.data.dataset import DatasetHdataset = DatasetH(handler={"class": "Alpha158", "module_path": "qlib.contrib.data.handler"}, segments={"train": ("2020-01-01", "2023-12-31")})- 此功能支持滚动窗口分割,避免前视偏差。
- 高性能检索:DataServer使用NumPy数组缓存,适用于TB级数据。基准显示,在多核CPU下,QLIB比Pandas快3-5倍。
- 市场动态适应:通过概念漂移检测(concept drift),自动调整数据权重,支持元学习。
4.2 模型训练模块
QLIB支持监督学习(SL)、市场动态建模(MDM)和强化学习(RL)三范式。
- 监督学习:内置LightGBM、CatBoost、MLP。训练过程包括交叉验证和早停。 示例(Transformer模型):
- Python
from qlib.contrib.model.pytorch import TransformerModelmodel = TransformerModel(d_model=64, nhead=8)model.fit(X_train, y_train)- 市场动态建模:使用TFT(Temporal Fusion Transformer)捕捉时变因子。 功能:自动处理非平稳性,支持多模态输入(价格、新闻)。
- 强化学习:集成PPO、OPDS用于订单执行优化。 示例(TWAP策略):
- Python
from qlib.rl.order_execution import TWAPAgentagent = TWAPAgent()rewards = agent.train(env=market_env, episodes=1000)- RL模块模拟滑点和流动性,优化执行路径。
4.3 策略生成与回测
策略模块包括信号生成和执行器。
- 信号策略:TopkDropout(Top-K选股+动态掉落),Enhancer(增强信号)。 示例:
- Python
from qlib.contrib.strategy.enhancer import EnhancerStrategyenhancer = EnhancerStrategy(base_strategy=base_strat, enhancer_model=mlp_enhancer)- 回测引擎:支持向量化和事件驱动模式,处理交易成本、滑点。 功能:多线程并行,输出持仓曲线、夏普比率。
4.4 风险分析与优化
- 风险模型:因子风险模型(FRM),计算边际风险贡献。 示例:
- Python
from qlib.risk import RiskModelrisk_model = RiskModel(cov_matrix)risk_exposure = risk_model.compute_risk(pred_score)- 优化器:CVaR(条件价值-at-风险)优化,支持约束(如杠杆限制)。
4.5 在线服务与部署
QLIB-Server支持低成本在线预测,自动滚动更新模型。
扩展能力
QLIB的模块化设计赋予其强大扩展性,用户可自定义组件而不改动核心代码。
5.1 自定义模型
继承BaseModel接口实现新模型。
示例(自定义LSTM):
Python
from qlib.model.base import BaseModelclass CustomLSTM(BaseModel): def __init__(self, d_model=64, num_layers=2): super().__init__() self.lstm = nn.LSTM(d_model, d_model, num_layers) def fit(self, dataset): # 训练逻辑 pass def predict(self, dataset): # 预测逻辑 pass注册后,可在YAML中调用。
5.2 自定义数据集
扩展DataHandler添加新因子。
示例:
Python
from qlib.data.dataset.handler import Alpha158class CustomHandler(Alpha158): def get_factor(self, *args): # 添加自定义因子,如波动率 return super().get_factor() + volatility_feature5.3 工作流扩展
支持嵌套执行(如RL内嵌SL)和RD-Agent集成,实现自动化因子挖掘。 示例:RD-Agent demo(https://rdagent.azurewebsites.net/)自动生成Alpha策略。
5.4 性能优化扩展
用户可集成Dask分布式计算,处理海量数据。
接口
QLIB无缝集成主流库,提升兼容性。
6.1 ML框架接口
- PyTorch/TensorFlow:模型层支持torch.nn和tf.keras,用户可混合使用。 示例:Transformer模型直接调用torch API。
- LightGBM/XGBoost:内置wrapper,自动处理金融数据格式。
6.2 数据接口
- Pandas/NumPy:数据API返回DataFrame,便于转换。
- TA-Lib:集成技术指标计算。
6.3 外部服务接口
- Polygon API:通过代理访问实时数据(代码环境内置key)。
- Qlib-Server:RESTful API部署,支持Docker。
6.4 生态集成
与Hugging Face Transformers集成高级NLP因子;与Ray Tune超参数优化。这些接口确保QLIB嵌入现有工作流。
基于QLIB的产品
7.1 RD-Agent
微软2024年推出的LLM代理,基于QLIB自动化R&D。功能:因子挖掘、模型优化。Demo展示自动生成年化回报15%的策略。
7.2 Quant Model Zoo
内置SOTA模型库,包括KRNN、Sandwich。用户可fork扩展成产品。
7.3 社区产品与案例
- Kaggle竞赛:QLIB用于msqlib数据集,获胜策略基于Alpha360。
- 商业应用:中国基金公司使用QLIB构建智能投顾,处理TB级数据。
- 教程产品:YouTube系列(如LSTM预测),Medium指南。
案例:Vadim博客演示LightGBM工作流,年化回报模拟达12%。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/10137