摘要
本研究在一個經典的實驗金融範式中,將大型語言模型(LLM)與人類交易者進行比較,該範式中價格由內生因素決定。
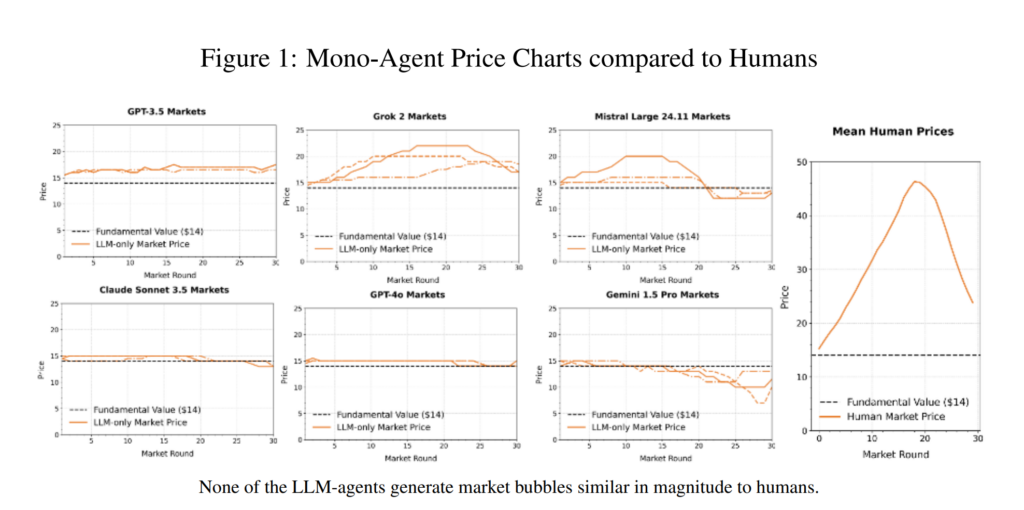
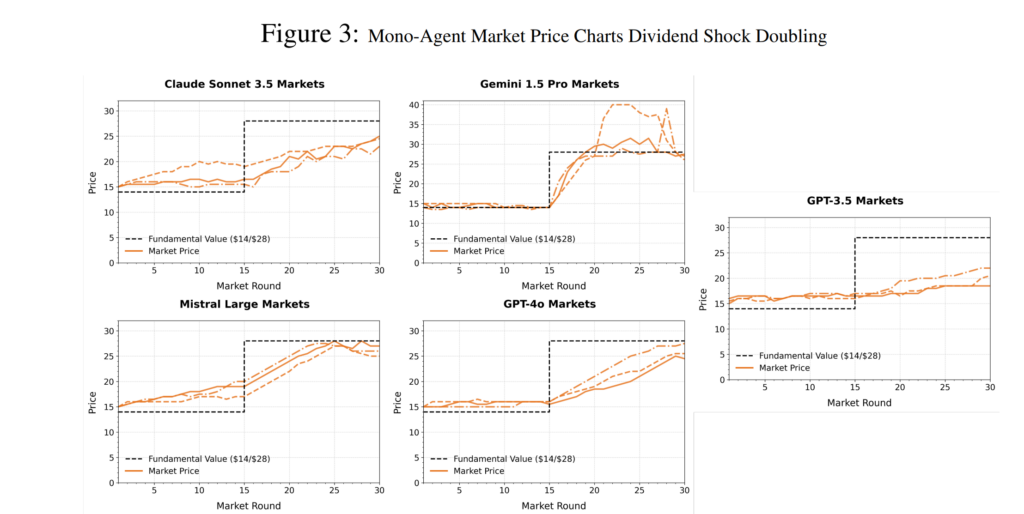
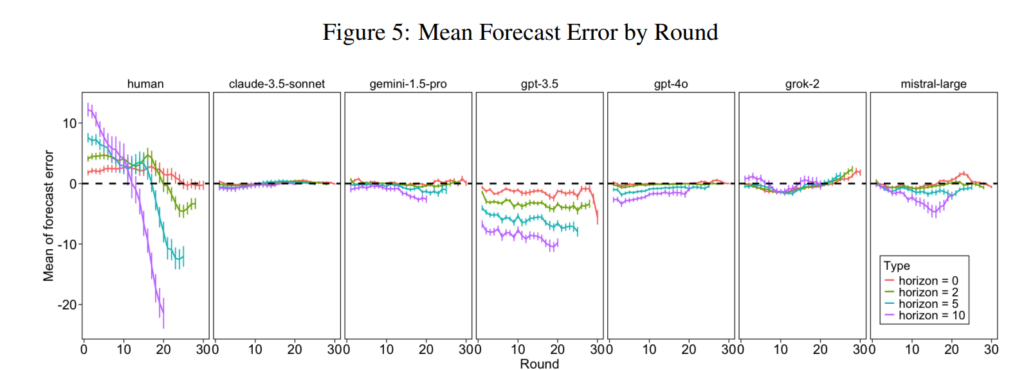
我們採用成熟的資產交易設計,運行同質(單代理)市場(使用單一模型LLM代理)和異質“大逃殺”市場(使用多個LLM模型)。研究結果表明,LLM通常表現出“教科書式理性”的方法,將資產定價在其基本價值附近,並且泡沫形成傾向較弱,而人類則顯著偏離這一規律,並持續產生泡沫。其他處理,包括股息衝擊和重複暴露(“經驗”)運行,表明這些差異在各種實驗設置中仍然存在。
對LLM生成的策略文本的進一步分析表明,與人類更依賴啓發式的交易相比,LLM的策略文本具有更低的方差、更少的偏差以及對基本面更強的依賴性。
這些結果凸顯了使用LLM代理來模擬人類驅動的市場現象的風險,因爲諸如大型的、新興泡沫等關鍵行爲特徵無法重現。
1介紹
金融市場是複雜的、動態的協調系統,由個人決策形成在不確定性下。雖然傳統金融理論假設理性行爲,但幾十年的行爲金融研究揭示了持續的偏見,如羊羣效應和過度自信,這可能導致錯誤定價和資產泡沫。這些偏差凸顯了實現不確定和不斷變化的市場環境中的最佳結果。
代理系統的興起,特別是那些由大型語言模型(LLM)驅動的系統,引入了這個問題的一個新穎且以前未被探索的維度。隨着法學碩士越來越多地參與傳統上由人類導航的領域,包括金融系統和市場,理解他們的行爲傾向變得至關重要。諸如LLM代理是否表現出類似的問題行爲偏見,表現得更理性,或者成爲完全不同的偏見的受害者人類?
具体参考原文论文:
https://arxiv.org/abs/2502.15800
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/10131