WebGPU 的推出改变了游戏规则,使 Web 客户端能够运行计算繁重的代码。WebGPU 计算管道的众多功能中,最突出的是它能够释放并行处理能力,为开发人员提供优化和加速其应用程序的强大工具。
WebGPU
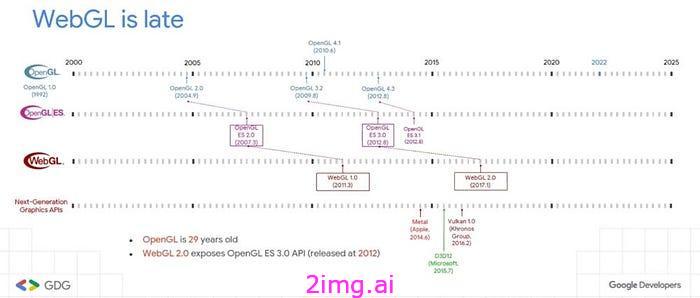
WebGPU 是 WebGL 的继任者,它提供了一个低级 API,允许开发人员直接与 GPU(图形处理单元)交互,与 WebGL 等高级抽象相比,它具有更多的控制和更好的性能。它引入了一种更现代、更高效的方法来处理 Web 应用程序中的图形和计算任务,这与下一代图形 API(DirectX 12、Metal 和 Vulkan)更相似。

在底层,WebGPU 进程被映射到运行代码的特定平台的图形 API 上的命令(Apple 为 Metal,Windows 为 DirectX 12,除 Apple 之外的所有平台为 Vulkan)。
为此,WebGPU API 采用与这些 GPU API 相同的大部分流程——例如创建缓冲区和编码器以在 CPU 和 GPU 之间传递数据和命令。
GPU 与 CPU
那么在 Web 中使用 GPU 而不是 CPU 有什么好处呢?首先,GPU 对于在 Web 环境中高效渲染任何 3D 查看器或图像查看器至关重要。Web html 画布使用 GPU 进行快速矩阵数学运算,以决定如何一次性绘制单个像素,而不是按顺序绘制(这会花费更长的时间)。
有了 WebGL,我们实际上可以使用 GPU 完成所有任务。随着 WebGPU 的推出,用户现在可以访问通用计算管道,从而允许他们使用 GPU 执行一般任务!这使我们能够直接在客户端执行 ML 推理、音频处理、物理模拟和其他非图形、可并行化的任务,而不是向某个服务器发送数据或从某个服务器发送数据来进行计算。
代码
在本文中,我们将使用 WebGPU 的计算管道,通过每次减少 10 倍来获取给定数组的总和(因此,一个线程对原始数组中的 10 个数字求和,并传回其部分的 1 个总和)。
这需要在基于 Web 的设置(即非节点)中完成,因为 WebGPU API 位于 Window.navigator 属性中。我在本演练中使用了 React 和 typescript,但您可以随意使用任何您喜欢的设置。
WebGPUComputer.ts
我创建了一个类来封装与 WebGPU 的接口,这将是我们的大部分逻辑所在。
export class WebGPUComputer {
private _device: GPUDevice | undefined;
private _computePipeline: GPUComputePipeline | undefined;
private _commandEncoder: GPUCommandEncoder | undefined;
private readonly _computeShader: string;
private constructor(computerShader: string) {
this._computeShader = computerShader;
}
public static async init(computeShader: string): Promise<WebGPUComputer> {
const webGPUComputer: WebGPUComputer = new WebGPUComputer(computeShader);
await webGPUComputer._initWebGPU();
await webGPUComputer._initComputePipeline();
return webGPUComputer;
}
public run(bindGroups: GPUBindGroup[], sourceBuffer: GPUBuffer, destinationBuffer: GPUBuffer, workerGroups: number) {
if (!this._device || !this._computePipeline) {return}
this._commandEncoder = this._device.createCommandEncoder();
const computePass = this._commandEncoder.beginComputePass();
computePass.setPipeline(this._computePipeline);
for (let i = 0; i < bindGroups.length; i++) {
computePass.setBindGroup(i, bindGroups[i]);
}
computePass.dispatchWorkgroups(workerGroups);
computePass.end();
this._commandEncoder.copyBufferToBuffer(sourceBuffer, 0, destinationBuffer, 0, destinationBuffer.size);
this._device.queue.submit([this._commandEncoder.finish()]);
}
public createBuffer(size: number, usage: number): GPUBuffer | undefined {
if (!this._device) { return }
return this._device.createBuffer({
size: size,
usage: usage,
});
}
public writeToBuffer(buffer: GPUBuffer, data: Float32Array) {
if (!this._device) { return }
this._device.queue.writeBuffer(buffer, 0, data);
}
public createBindGroup(buffers: GPUBuffer[]): GPUBindGroup | undefined {
if (!this._device || !this._computePipeline) { return }
return this._device.createBindGroup({
entries: buffers.map((buffer, index) => {
return {
binding: index,
resource: {
buffer: buffer
}
}
}),
layout: this._computePipeline.getBindGroupLayout(0)
})
}
private async _initWebGPU() {
if (!navigator.gpu) {
throw new Error("WebGPU Not Supported");
}
const adapter = await navigator.gpu.requestAdapter({
powerPreference: "high-performance"
});
if (!adapter) {
throw new Error("Could not get adapter");
}
this._device = await adapter.requestDevice({
requiredLimits: {
maxStorageBufferBindingSize: adapter.limits.maxStorageBufferBindingSize
}
})
}
private async _initComputePipeline() {
if (!this._device) {return}
const descriptor: GPUComputePipelineDescriptor = {
layout: "auto",
compute: {
module: this._device.createShaderModule({
code: this._computeShader
}),
entryPoint: 'main'
}
}
this._computePipeline = await this._device.createComputePipelineAsync(descriptor);
}
}让我们从 init 函数和构造函数开始逐一分解代码。
初始化
private constructor(computerShader: string) {
this._computeShader = computerShader;
}
public static async init(computeShader: string): Promise<WebGPUComputer> {
const webGPUComputer: WebGPUComputer = new WebGPUComputer(computeShader);
await webGPUComputer._initWebGPU();
await webGPUComputer._initComputePipeline();
return webGPUComputer;
}init 函数创建一个新的 WebGPUComputer,初始化 WebGPU 并设置我们的计算管道,然后返回 WebGPUComputer 实例。为什么我要创建一个静态 init 函数而不是在构造函数中完成所有这些操作?因为构造函数不能是异步的,而且我们调用的一些设置代码会返回需要等待的承诺。
_initWebGPU
这是我们在构造过程中调用的第一个设置函数。
private async _initWebGPU() {
if (!navigator.gpu) {
throw new Error("WebGPU Not Supported");
}
const adapter = await navigator.gpu.requestAdapter({
powerPreference: "high-performance"
});
if (!adapter) {
throw new Error("Could not get adapter");
}
this._device = await adapter.requestDevice({
requiredLimits: {
maxStorageBufferBindingSize: adapter.limits.maxStorageBufferBindingSize
}
})
}我们首先检查客户端上是否启用了 WebGPU(很多浏览器都没有启用https://caniuse.com/webgpu)。然后我们请求一个适配器,它就像一个虚拟 GPU 设备接口,让我们请求并获取实际的 GPU 设备,我们将 maxStorageBufferBindingSize 设置为适配器所具有的那个 — — 因为默认设备的 maxStorageBufferBindingSize 非常小。
_initComputePipeline
private async _initComputePipeline() {
if (!this._device) {return}
const descriptor: GPUComputePipelineDescriptor = {
layout: "auto",
compute: {
module: this._device.createShaderModule({
code: this._computeShader
}),
entryPoint: 'main'
}
}
this._computePipeline = await this._device.createComputePipelineAsync(descriptor);
}接下来我们初始化管道本身,创建一个使用 GPU 设备的描述符和一个 computeShader 字符串,我们在构造时传入该字符串以创建 ShaderModule。computeShader 是一个字符串,它包含我们将在 GPU 上运行的 WGSL 代码(稍后会详细介绍)。
一旦我们设置了描述符,我们就可以创建计算管道。
createBuffer 和 writeToBuffer
现在我们已经设置好了管道,但在运行任何程序之前,我们必须将一些数据传递给 GPU,以便 GPU 可以引用这些数据。缓冲区是我们向 CPU 和 GPU 之间传递数据的方式。我们的写入和创建缓冲区方法将让我们能够将数据从 CPU 传递到 GPU。
public createBuffer(size: number, usage: number): GPUBuffer | undefined {
if (!this._device) { return }
return this._device.createBuffer({
size: size,
usage: usage,
});
}
public writeToBuffer(buffer: GPUBuffer, data: Float32Array) {
if (!this._device) { return }
this._device.queue.writeBuffer(buffer, 0, data);
}createBuffer 接收缓冲区的大小(以字节为单位)以及其用途(即写入数据或读取数据)。如果我们成功创建缓冲区,我们将它返回给调用者。
然后调用者可以 writeToBuffer 并传入他们创建的缓冲区和一些要写入的数据。device.queue.writeToBuffer 接受要写入的缓冲区、开始写入的位置的字节偏移量以及要写入的数据。
创建绑定组
创建缓冲区是不够的,我们需要赋予它某种标识,以便我们的 GPU 可以访问它,这就是绑定组发挥作用的地方。
public createBindGroup(buffers: GPUBuffer[]): GPUBindGroup | undefined {
if (!this._device || !this._computePipeline) { return }
return this._device.createBindGroup({
entries: buffers.map((buffer, index) => {
return {
binding: index,
resource: {
buffer: buffer
}
}
}),
layout: this._computePipeline.getBindGroupLayout(0)
})
}我们获取要添加到组中的缓冲区列表,然后使用 GPU 设备创建一个包含所有缓冲区的绑定组。我们在此示例中使用 bindGroupLayout 0,如果您想创建多个绑定组,我们将更改此值。
我们的 WGSL 代码现在可以通过其绑定组引用我们的缓冲区,如@group(0) @binding({index})。
运行
最后,现在所有设置都已完成,我们就可以运行计算管道了。
public run(bindGroups: GPUBindGroup[], sourceBuffer: GPUBuffer, destinationBuffer: GPUBuffer, workerGroups: number) {
if (!this._device || !this._computePipeline) {return}
this._commandEncoder = this._device.createCommandEncoder();
const computePass = this._commandEncoder.beginComputePass();
computePass.setPipeline(this._computePipeline);
for (let i = 0; i < bindGroups.length; i++) {
computePass.setBindGroup(i, bindGroups[i]);
}
computePass.dispatchWorkgroups(workerGroups);
computePass.end();
this._commandEncoder.copyBufferToBuffer(sourceBuffer, 0, destinationBuffer, 0, destinationBuffer.size);
this._device.queue.submit([this._commandEncoder.finish()]);
}我们传入我们的 bindGroup(s),我们想要的 workerGroups 的数量(用于确定要运行的线程数),并且 – 对于这个例子 – 我们还将传入对缓冲区的引用,因为我们将把数据从结果缓冲区复制到读取缓冲区,然后我们的 CPU 就可以访问该缓冲区。
我们将要执行的操作写入一个commandEncoder,然后这些命令在该函数结束时提交给GPU执行。
应用程序.tsx
现在,大多数 WebGPU 代码都封装在我们的类中,这样我们就可以更轻松地从 App.tsx 运行一些 GPU 代码
import {WebGPUComputer} from "./WebGPUComputer";
import {sum10} from "./comp";
export const App = () => {
const startCompute = async () => {
// CPU to verify
let arrSize = 100000;
let data = new Float32Array(Array.from({length: arrSize}, () => Math.random()));
console.log(data.reduce((previousValue, currentValue) => previousValue + currentValue))
// GPU run
const webGPUComputer: WebGPUComputer = await WebGPUComputer.init(sum10);
while (data.length > 1) {
const dataBuffer: GPUBuffer = webGPUComputer.createBuffer(data.byteLength, GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST)!;
webGPUComputer.writeToBuffer(dataBuffer, data);
const resultBuffer: GPUBuffer = webGPUComputer.createBuffer(Math.ceil(data.length / 10) * 4, GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC)!;
const bindGroup: GPUBindGroup = webGPUComputer.createBindGroup([dataBuffer, resultBuffer])!;
const readBuffer: GPUBuffer = webGPUComputer.createBuffer(Math.ceil(data.length/ 10) * 4, GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST)!;
webGPUComputer.run([bindGroup], resultBuffer, readBuffer, data.length/10);
await readBuffer.mapAsync(GPUMapMode.READ);
data = new Float32Array(readBuffer.getMappedRange());
}
console.log(data);
}
return (
<div>
<button onClick={() => startCompute()}>Compute</button>
</div>
)
}我们创建一个包含 100000 个浮点数的数组,并首先在 CPU 上对它们求和,以验证我们的 GPU 代码的准确性。
我们的 GPU 计算着色器将运行多次,因为每个线程对 10 个数字求和,所以我们将从 100000 -> 10000 -> 1000 -> … -> 1。
首先,我们创建一个与当前数字列表大小相同的缓冲区,并告诉 GPU 它将用作存储,我们将使用 COPY_DST 标志将数据复制到其中。然后我们将数据写入其中。
我们创建另一个结果缓冲区,其大小为数据缓冲区的十分之一(因为我们将数组大小减少 10),并告诉 GPU 这将用作复制源。然后,我们创建数据和结果缓冲区的绑定组,以便我们可以在 GPU 上使用它们。
我们创建一个与结果缓冲区大小相同的读取缓冲区,它将用作我们将结果数据复制到的目的地,并且我们还赋予它 MAP_READ 标志,因为我们将把它映射到 CPU 并读出它。
接下来,我们使用 data.length/10 workerGroups 运行着色器代码,这样做是因为在我们的例子中,workerGroups 的数量 = 线程数,每个线程将总结 10 个条目,因此我们的数据中每 10 个项目只需要 1 个线程。
最后,我们将读取缓冲区数据移动到 CPU 并将其提取到我们的数据变量中。
压缩文件
现在到了最后一部分,也就是我们将在 GPU 上运行的实际代码。我将其放入 ts 文件中,以便将其作为字符串轻松导入 app.tsx
export const sum10 = "@group(0) @binding(0) var<storage, read> data: array<f32>;\n" +
"@group(0) @binding(1) var<storage, read_write> result: array<f32>;\n" +
"\n" +
"@compute @workgroup_size(1)\n" +
"fn main(@builtin(global_invocation_id) global_id: vec3<u32>) {\n" +
" let index = global_id.x;\n" +
" var sum: f32 = 0;\n" +
" for (var i = index * 10; i < (index + 1) * 10; i++) {\n" +
" sum += data[i];\n" +
" }\n" +
"\n" +
" result[index] = sum;\n" +
"}"但直接将其写入 .wgsl 文件中会更好
计算.sum10.wgsl
@group(0) @binding(0) var<storage, read> data: array<f32>;
@group(0) @binding(1) var<storage, read_write> result: array<f32>;
@compute @workgroup_size(1)
fn main(@builtin(global_invocation_id) global_id: vec3<u32>) {
let index = global_id.x;
var sum: f32 = 0;
for (var i = index * 10; i < (index + 1) * 10; i++) {
sum += data[i];
}
result[index] = sum;
}在顶部,我们可以看到两个缓冲区——结果和数据——我们将在整个主函数中使用它们。
我们用 @compute 注释该函数,以便我们的 GPU 知道我们尝试执行哪种操作。我们还将 workgroup_size 指定为 1,以便每个 workerGroup 运行 1 个线程。因此总线程数 = num workerGroups * workgroup_size。
这个函数使用一个叫做 global_invocation_id 的内置变量,它告诉我们我们是哪个线程,我们将使用这个 id 来确定数组中我们要求和的项目(例如,线程 2 求和 20-30,线程 90 求和 900-1000)。
我们计算这 10 个数字的总和,并将结果数组中与我们的线程索引相对应的条目设置为总和。
结论
看完本介绍后,您应该对如何设置 WebGPU 来运行计算着色器有了基本的了解。您可以将其用作模板,为要在客户端执行的任何并行任务创建其他 WebGPU 计算管道。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6236