为寻求克服生产环境中 RAG 挑战的从业者提供可行的见解和实用工具!
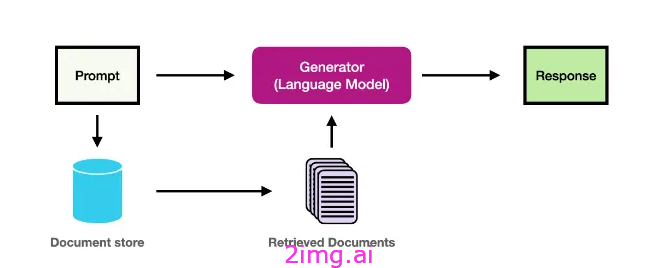
在将检索增强生成 (RAG) 集成到生产系统的过程中,我遇到了一些在原型设计阶段并不总是立即可见的挑战。RAG 将生成模型与检索机制相结合以访问外部知识,在提高语言模型的质量和事实准确性方面具有巨大的潜力。然而,将 RAG 投入生产会带来一系列独特的复杂性。在这里,我将深入探讨五个关键挑战,并根据我的发现和实践经验提供实用的解决方案。
挑战 1:保持高质量的检索结果
问题:
检索到的文档的质量对于 RAG 的成功至关重要。低质量的检索会降低生成输出的准确性和相关性,这在专业化或技术含量高的领域尤其成问题。
缓解策略:
为了提高检索质量,我建议使用对比学习技术来微调检索器。此外,使用转换器的上下文嵌入可以更好地理解查询的语义,从而提高结果的质量。
在领域特异性至关重要的情况下,使用SBERT (Sentence-BERT)等模型集成文档嵌入可以增加额外的语义相似度评分层。这样就可以检索更多上下文相关的文档。
工具:
- SBERT(Sentence-BERT):一种转换模型,可捕捉查询和文档之间的语义相似性,从而增强检索器的性能。
- 密集检索工具包:一组将密集段落检索 (DPR) 模型与特定领域微调相结合的工具。
- ColBERT:一种专为高效检索而设计的先进双编码器模型,在处理大型文档存储时特别有用。
提示:
考虑在密集检索之前使用关键字搜索等预过滤机制。这种混合方法可以显著减少搜索空间,而不会失去相关性。
挑战 2:延迟和可扩展性瓶颈
问题:
由于检索步骤,RAG 引入了额外的延迟。随着文档语料库的增长,检索速度会变慢,尤其是在底层基础设施无法充分扩展的情况下。
缓解策略:
除了缓存结果之外,使用异步检索来并行化请求可以缩短响应时间。另一种有用的方法是使用矢量量化来降低矢量表示的维数,从而加快相似性搜索的速度。
在具有分布式向量索引的分布式搜索引擎(例如OpenSearch或ElasticSearch)上部署检索组件是处理大规模检索任务的关键。这些引擎允许跨集群进行水平扩展,从而减少延迟。
工具:
- OpenSearch:一种分布式搜索引擎,可以与基于向量的检索很好地集成,同时保持可扩展性。
- Milvus:高度可扩展的向量数据库,支持数十亿条向量,并实现低延迟检索。
- PyTorch 的 RPC:用于构建并行包含检索和生成步骤的可扩展分布式系统。
提示:
对于文档密集型应用程序,利用近似最近邻 (ANN)算法(例如 HNSW)快速缩小候选文档范围,从而即使在大型数据集的情况下也能减少检索延迟。
挑战 3:处理嘈杂或不完整的知识库
问题:
在现实场景中,知识库可能不完整或充满噪音。这会导致检索组件返回不相关或不正确的信息,从而破坏生成的响应。
缓解策略:
除了定期更新外,我建议使用无监督异常检测技术来过滤掉不相关或超出域的内容。像Anomaly Transformer这样的工具可以检测和删除噪声数据。您还可以使用知识图谱增强,其中集成了结构化知识图谱来验证和增强检索到的数据。
另一种技术是使用文档排名算法,该算法不仅依赖于相关性,还依赖于基于元数据、时间戳和特定领域相关性指标的可信度分数。
附加工具:
- 异常变换器:一种无监督模型,用于检测非结构化文档集合中的异常值,去除噪声或不相关的数据。
- Stanza:一个多语言 NLP 库,有助于预处理和清理噪声数据,对于实体识别、句子拆分和解析等任务特别有用。
- DGL(深度图库):创建知识图谱并使用结构化信息增强您的检索过程。
提示:
设置文档重复数据删除管道以消除冗余信息,确保只检索最新和最相关的文档。Dedup 等工具可以帮助简化此过程。
挑战 4:管理检索广度和深度之间的权衡
问题:
在广泛检索(捕获所有相关文档)和深度检索(关注最相关的文档)之间找到适当的平衡通常很困难。广泛检索策略可能会带来不相关数据的风险,而狭义检索可能会错过重要的背景信息。
缓解策略:
多向量检索方法可以帮助平衡这种权衡。借助ColBERTv2等模型,它利用多个向量来表示文档的不同方面,您可以检索涵盖查询的更广泛和更深方面的文档。此外,查询扩展技术(例如添加同义词或相关概念)可以在不牺牲深度的情况下增加结果的广度。
此外,结合相关反馈循环(利用用户对检索到的文档的反馈来微调未来的检索)可以显著提高系统性能。
工具:
- ColBERTv2:一种基于变压器的模型,专为多向量检索而设计,可捕捉文档的各种语义细微差别。
- Anserini:一种信息检索工具包,支持结合稀疏和密集检索的混合检索技术,平衡广度和深度。
- Word2Vec和GloVe嵌入用于查询扩展,允许检索系统根据语义相关术语投射更广泛的网络。
提示:
使用动态查询重新加权,根据用户上下文或偏好调整查询的重要性。此技术可确保动态地为相关术语赋予更多权重,从而提高检索深度。
挑战5:集成复杂性和保持模块化灵活性
问题:
RAG 系统有几个相互连接的组件——检索器、排序器和生成器——这使得保持灵活性、可扩展性和持续改进变得具有挑战性。
缓解策略:
缓解这种情况的一种方法是采用容器化微服务。每个模块(检索、排名和生成)都可以使用Docker进行容器化,并使用Kubernetes进行编排,从而确保无缝扩展和模块灵活性。功能切换在此设置中也变得至关重要,您可以根据需要打开或关闭不同的检索或生成机制,而不会破坏整个系统。
可以使用GitLab等工具构建自动化 CI/CD 管道来维护持续集成环境,确保任何改进或新功能都被推送到生产中,而不会影响整体系统可靠性。
工具:
- Triton 推理服务器:一种生产就绪的服务器,允许您将 RAG 模型部署为微服务,同时优化资源利用率。
- Kubernetes Helm Charts:使用预定义模板独立管理和扩展 RAG 组件。
提示:
考虑对某些组件(如检索)使用无服务器架构来运行轻量级检索任务,根据负载进行扩展并减少运营开销。
全面且工具丰富的 RAG 实施方法
在生产中构建和部署 RAG 系统面临着独特的挑战。作为一名从业者,我曾面临检索质量、延迟、知识库中的噪音和集成复杂性等问题。但是,通过正确的策略和工具组合,可以有效解决这些挑战。SBERT、ColBERT 和 OpenSearch 等高级检索模型与语义缓存和多阶段排名相结合,可以确保高质量、低延迟的结果。
展望未来,RAG 的未来将涉及更智能的个性化、实时学习和知识图谱的更深入集成,从而使系统变得更具适应性和精确性。跨模式检索将通过集成各种数据类型来丰富生成输出,而编排框架将处理日益复杂的工作流程。通过为这些趋势做好准备并不断优化您的 RAG 系统,您可以保持领先地位,充分利用 RAG 来解决现实世界的挑战。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6319