前言
上一节中我们对课程进行介绍
本节我们开始讲解第一节课程,LoRA模型的基本理解
总体来看,LoRA主要的发力点在于高性能,小尺寸,好效果。主要发挥的方面可能是图像风格转换,局部风格调整,神经网络架构自适应特征调整,并且在人像美化、景观增强等方面有着广泛的应用前景。
简单而言,LoRA模型可以让你在一个很大的模型基础上,调配出来你想要的分支细分能力。站在巨人的肩膀上。
本文知识点
- 介绍LoRA模型和应用
基础知识
一、Lora模型的解释和应用
本节课程我们通过简介和图片示例,先来简单的认识了解一下Lora模型。
1、为什么要训练Lora模型
1.1 降低当前设备的性能要求
Lora采用的方式是向原有的模型中插入新的数据处理层,这样就避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法。
直接以矩阵相乘的形式存储,最终文件就会小很多。
Lora模型,只需要少量的素材集和一般的设备性能即可完成训练,而且模型体积相比大模型非常小(一般常见的8M-144M)。而一般的DB大模型至少都是近2G起,节省了大量的存储空间
大模型的训练时,对于机器的设备性能要求更高,比如使用Dreambooth去训练大模型,那么你的显卡显存至少要12G以上,这对于设备性能一般的同学,有些过于奢侈了。
Lora训练时需要的显存也少了,显卡的显存达到6G 即可开启训练,硬件门槛更加亲民。
1.2 更加灵活满足各种需求
Lora可以非常方便的在webui界面通过调用和不同权重,实现多种模型效果的叠加,相比DB大模型操作更加便捷,效果更加显著。一个好的Lora模型效果并不会输给某些大模型。
现在市面上有很多已经训练好的大模型,涉及到很广的范围,比如人物、动物、植物,游戏场景、建筑、空间、二次元、画风等等。但是,根据自身实际需求,这些可能依然不能满足你对某个或者某些需求的定制。
那么这时候,你就可以通过定制训练Lora模型来满足自己的需求。
2、Lora模型是什么?
LoRA(Low-Rank Adaptation)是一种用于微调Stable Diffusion模型的训练技术。
但我们已经有了其他的训练技术,例如 Dreambooth 和 文本反转。那么 LoRA 有何特别之处呢?
LoRA 在文件大小和训练能力之间取得了良好的平衡。
Dreambooth 功能强大,但模型文件体积较大(2-7 GB)。文本反转模型很小(约100 KB),但功能有限。
除了LoRA,其他常用的模型有CheckPoint、VAE、Embeddings、Hypernetwork等。
常用五大模型特征图:
| 模型名称 | 模型特点 | 模型擅长 | 模型后缀 | 模型大小 |
|---|---|---|---|---|
| CheckPoint | 主模型、素材丰富、体积大、占用内存大 | 人物、画风等 | safetensors、ckpt等 | 2G、4G、7G(均可修剪为2G,效果无差别) |
| Lora | 微调模型、人/物/画风定制、体积小、效率高 | 推荐人物,其次画风,概念 | safetensors、ckpt、pt等 | 8M-144M |
| VAE | 美化模型、色彩美化、体积小 | 色彩调节 | ckpt、pt等 | 几十kb |
| Embedding | 嵌入模型、调试文本理解、反向嵌入、正向嵌入(同Lora)、体积小 | 推荐人物,其次画风 | pt等 | 几十kb |
| Hypernetwork | 超网络模型、细致画风处理及定制、难度高 | 推荐画风,其次人物,相比以上模型很少用 | pt等 | 小至kb,大至GB |
从以上特征图中可以看到,Lora模型包括训练、定制人物(包括真人、二次元)、物品、画风,体积小(占用内存小,一般100M左右)、训练效率高等优点,仅需要少量的数据集即可训练出属于自己的模型。
那么,学会了Lora模型的训练,你就可以依葫芦画瓢,调整其他模型对应的参数设置,应用到其他几个模型的训练上面。
Lora模型不仅可以影响整体的绘画效果,还可以对绘画效果及细节进一步的微调。
在出图调用过程中,Lora模型需要配合主模型的使用,实现对图片结果的调整优化输出。
举个例子
我们想象一下你有一辆车,这辆车已经可以满足你的日常需求,比如上班通勤。但有一天,你决定参加一场越野赛车比赛。你知道你的车在原有状态下无法应对越野赛的挑战,但你也不想换一辆新车。这时,你可以选择对你的车进行一些改装,比如换上越野轮胎、增强悬挂系统,这样你的车就能适应越野赛的环境。你的原始车辆就像是一个已经训练好的神经网络模型,它在大多数情况下都能很好地工作。
然而,当面对新的或特殊的任务(比如越野赛)时,它可能需要一些调整才能更好地适应。
LoRA(Low-Rank Adaptation)模型的作用就像是对车辆进行的这些特定改装。通过在原有模型上添加低秩矩阵(相当于对车辆的特定部分进行改装),我们可以使模型更好地适应新的任务,而不需要完全重新设计或训练一个新模型。
总体来看
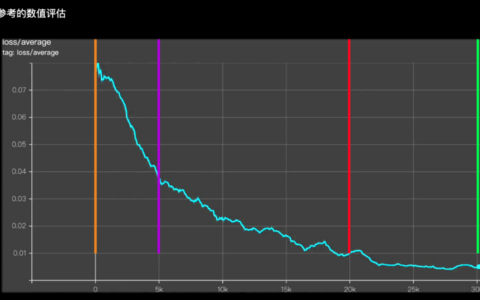
我们都知道,在RA/SD中作图时,出图结果是没有下限的,最终的图片可能是杂乱的,崩坏的,不符合我们预期的。那么我们一般是通过调整提示词、提示词的权重、甚至运用ControlNet等插件进行结合使用,优化出图,但是最终的图片效果可能依然达不到我们的预期。
那么这时候,我们就可以运用Lora模型的调用,来进一步优化我们的图片。
这也是为什么它可以作为一种微调模型使用。即在主模型固定的基础上,对人(包括五官、服饰、姿态等)、物品(特征细节、角度等)、画风(艺术风格、技法等)等细节进一步的微调,来达到自己理想中的出图状态和效果。
二 调用Lora模型的应用案例
现在让我们通过下面一些图片的示例,来确认一下同样提示词和参数设置下,没有调用和调用Lora模型后的效果区别。
2.1、人物Lora模型示例:


(调用宋慧乔的Lora模型前) (调用宋慧乔的Lora模型后)
2.2、画风Lora模型示例:


(调用画风Lora模型前) (调用画风Lora模型后)
通过以上图例我们可以看到,在相同的提示词和参数下,由RA/SD主模型出图的真人效果,无法实现我们对于某个真实存在的人物图像的直接呈现,但是调用了经过训练这个人物的Lora模型之后,就可以完成人物相貌的还原以及特效、场景的二次构造。
另外,在没有改善画质等特别提示词和相同的参数下,由RA/SD主模型出图的效果,整体色调会有些偏暗,构图简单、特效简单,但是调用了训练的Lora模型后,图片的整体风格、色彩色调、构图特效、细节优化等有了很大的加强、改善和提升。
如果,你会使用PhotoShop等软件,还可以对图片进行二次美化和合成处理,来达到你所需求的最终效果。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6476