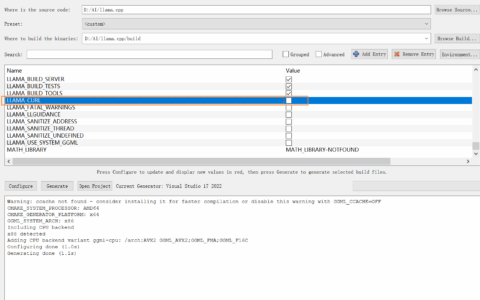
下载 Huggingface 模型
请使用 git LFS 克隆仓库
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B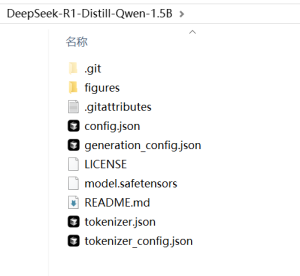
生成 GGUF 模型
提示
推荐使用 python3.11 以上版本
cd llama.cpp pip3 install -r ./requirements.txt python3 convert_hf_to_gguf.py DeepSeek-R1-Distill-Qwen-1.5B/ 或 python convert_hf_to_gguf.py ../DeepSeek-R1-Distill-Qwen-1.5B/ 第二个参数是你自己上一步下载模型的目录为止。 如下图中成功操作。
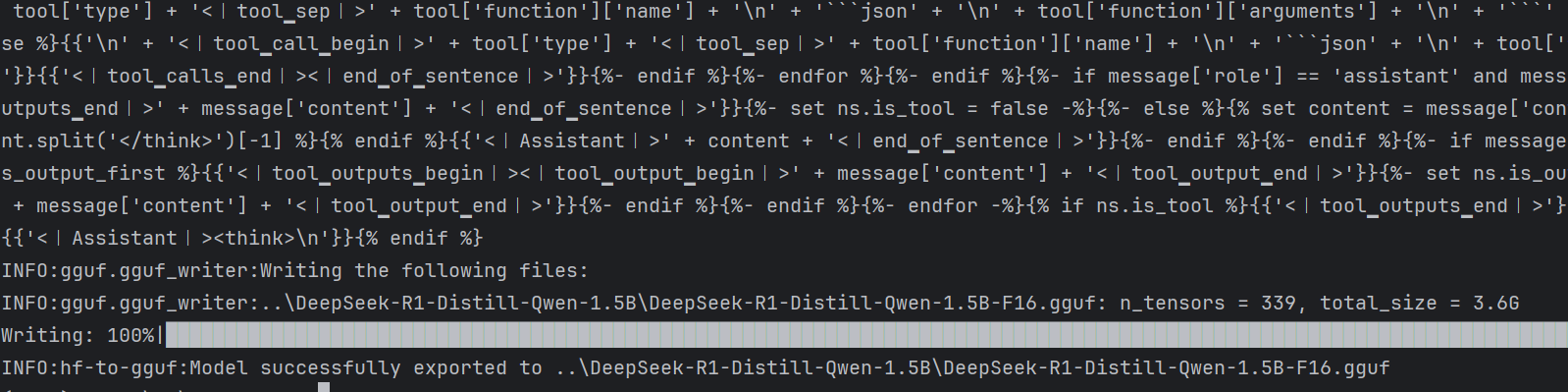
在上述下载的模型目录中,新生成了下图中的模型
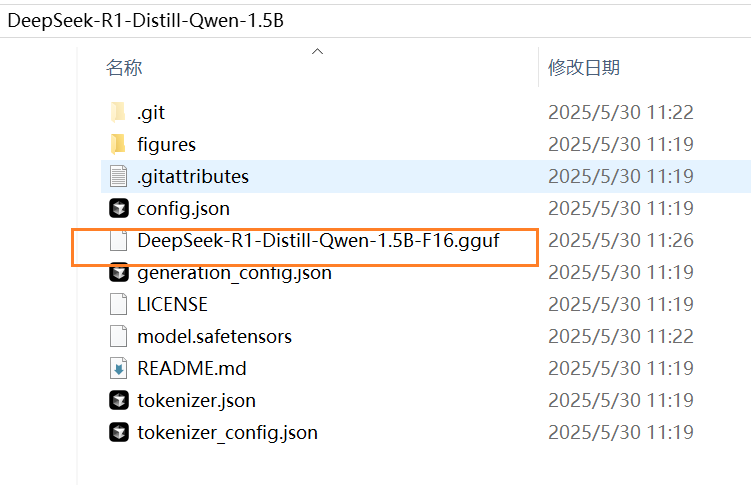
量化模型
cd build/bin ./llama-quantize DeepSeek-R1-Distill-Qwen-1.5B-F16.gguf DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf Q4_K_M 这个命令自行在你的环境中修改。 第一个命令是llama.cpp编译后的目录下的量化工具。 第一个参数是刚才生成的gguf模型 第二个参数量化后的模型名字,随意取 第三个参数是量化类型。具体参数选择如下 2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B 3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B 8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B 9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B 19 or IQ2_XXS : 2.06 bpw quantization 20 or IQ2_XS : 2.31 bpw quantization 28 or IQ2_S : 2.5 bpw quantization 29 or IQ2_M : 2.7 bpw quantization 24 or IQ1_S : 1.56 bpw quantization 31 or IQ1_M : 1.75 bpw quantization 36 or TQ1_0 : 1.69 bpw ternarization 37 or TQ2_0 : 2.06 bpw ternarization 10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B 21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B 23 or IQ3_XXS : 3.06 bpw quantization 26 or IQ3_S : 3.44 bpw quantization 27 or IQ3_M : 3.66 bpw quantization mix 12 or Q3_K : alias for Q3_K_M 22 or IQ3_XS : 3.3 bpw quantization 11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B 12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B 13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B 25 or IQ4_NL : 4.50 bpw non-linear quantization 30 or IQ4_XS : 4.25 bpw non-linear quantization 15 or Q4_K : alias for Q4_K_M 14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B 15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B 17 or Q5_K : alias for Q5_K_M 16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B 17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B 18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B 7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B 1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B 32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B 0 or F32 : 26.00G @ 7B COPY : only copy tensors, no quantizing

过程截图
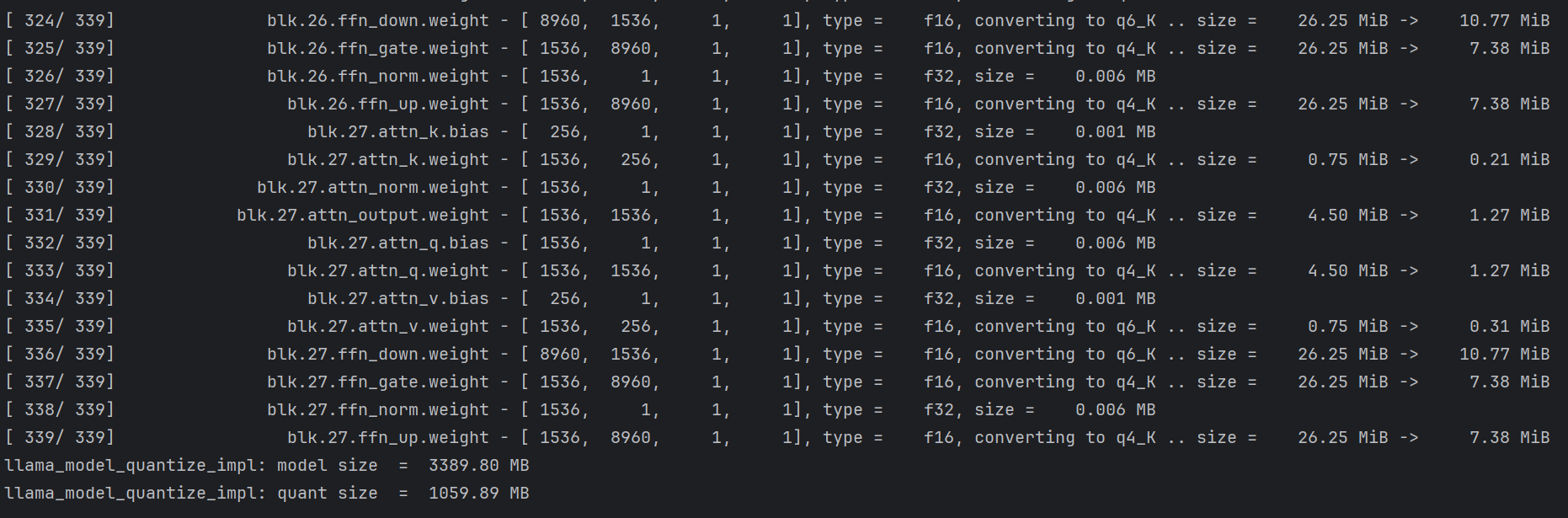
最终生成的模型。原来3.5G的模型量化后1.0G左右。

执行下面,加载模型。 .\llama-cli.exe -m .\DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
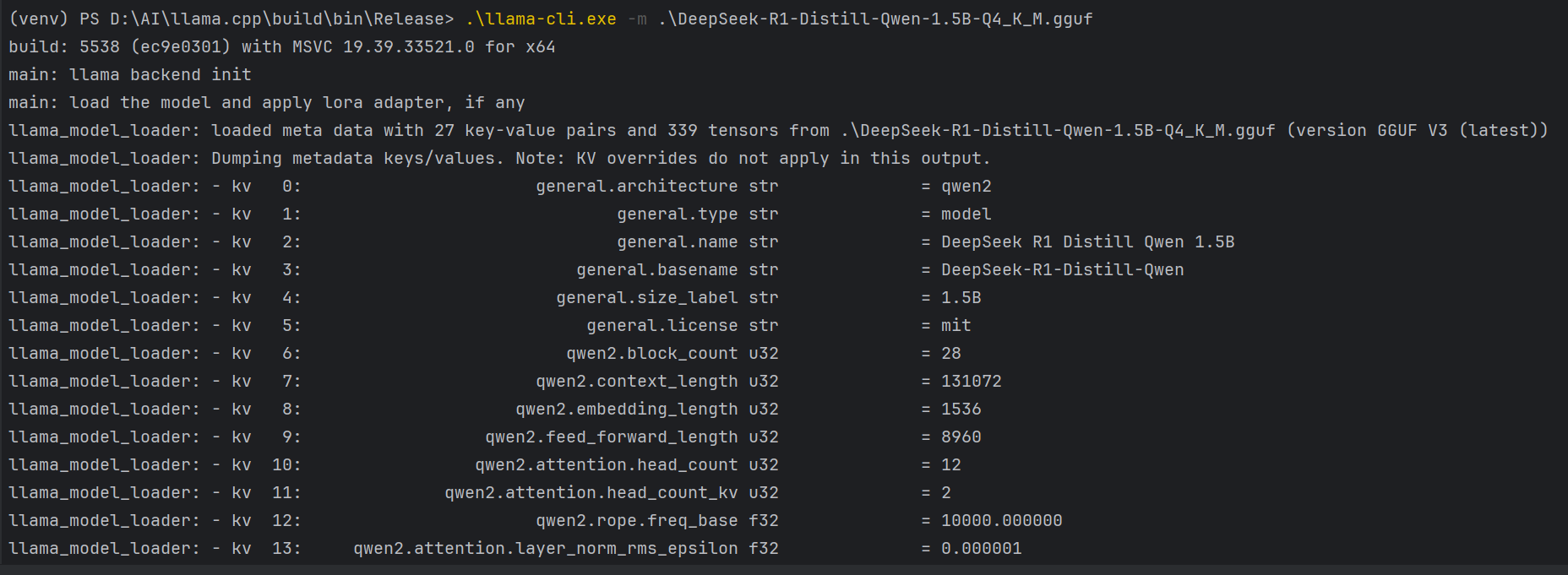
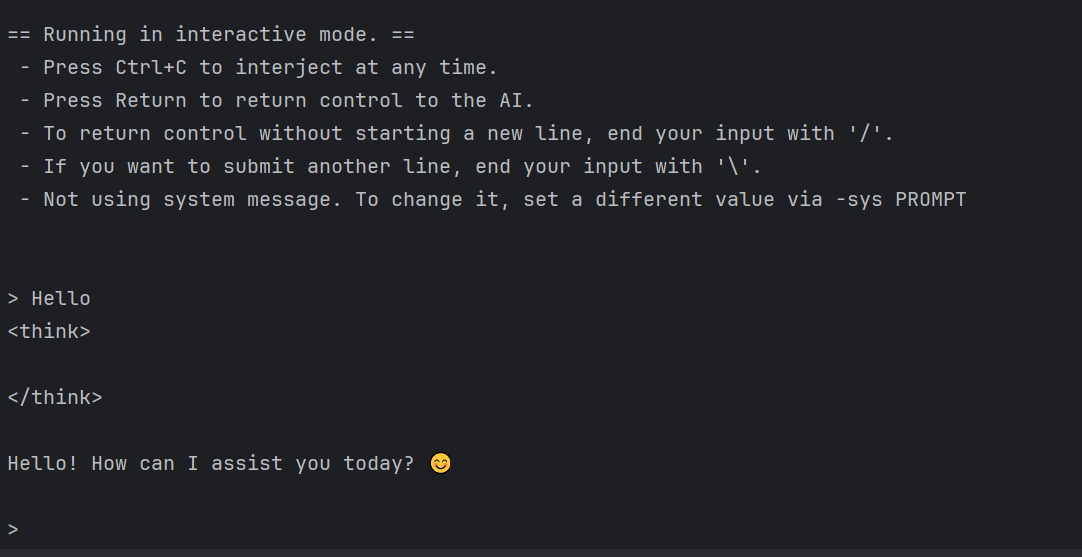
然后就直接在console中使用chat对话能力了
GGUF 基准测试
./llama-bench -m DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
更多AI技术博客: 2img.ai
更多前言科技探索: 2video.cn
更多个人专栏 : fuqifacai.github.com
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9761