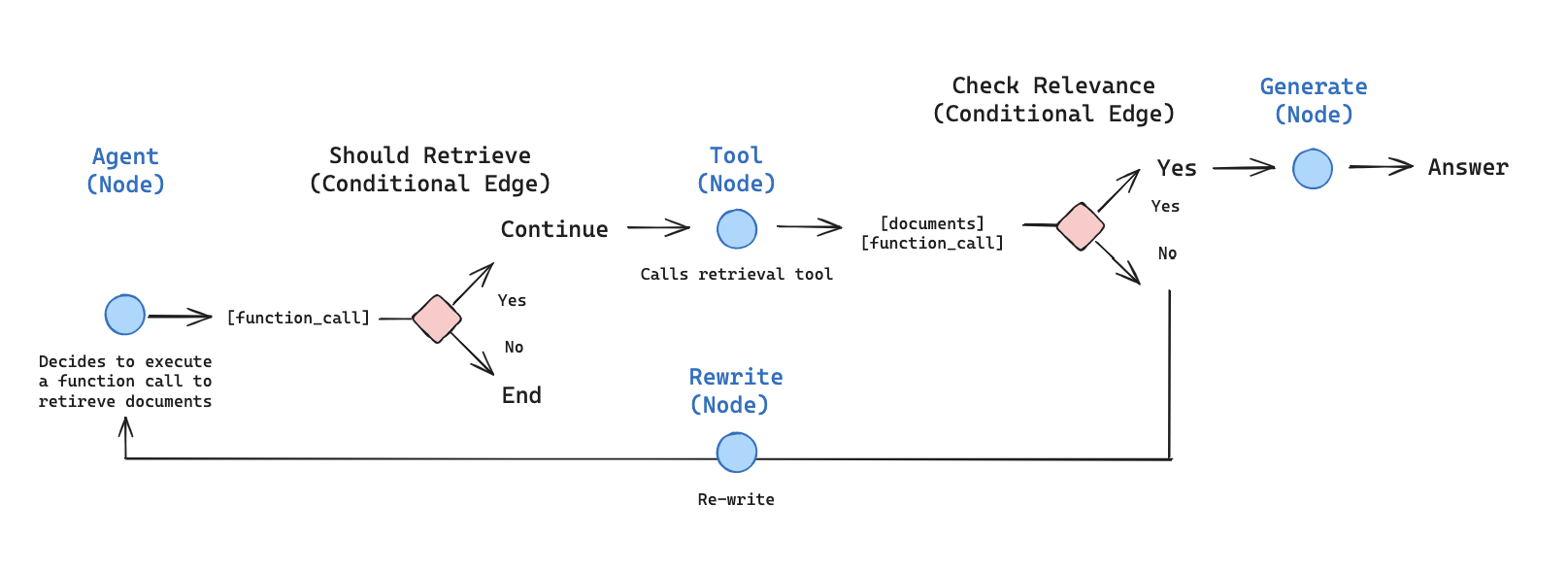
1 概述
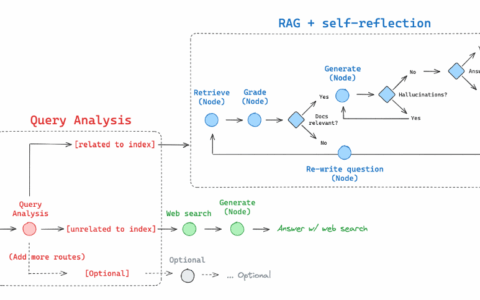
当我们想要决定是否从索引中检索时,检索代理很有用。
为了实现检索代理,我们只需授予 LLM 访问检索工具的权限。
该范式的特点:支持动态决策,例如是否调用检索工具、是否重写查询、是否生成最终答案。
2 主要内容
2.1 创建索引
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()切分策略:使用 RecursiveCharacterTextSplitter 将文档切分为小块(chunk_size=100,overlap=50),以适配向量数据库的检索需求。
设计理念:小块切分确保检索到的上下文更精准,overlap 保证语义连续性。
2.3 创建索引工具
功能:将向量数据库的检索器封装为一个 LangChain 工具,代理可以通过调用此工具检索相关文档。
设计理念:工具化的设计让 LLM 可以动态决定是否需要外部知识,符合 Agentic RAG 的灵活性。
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_blog_posts",
"Search and return information about Lilian Weng blog posts on LLM agents, prompt engineering, and adversarial attacks on LLMs.",
)
tools = [retriever_tool]2.4 状态定义
- AgentState:
from typing import Annotated, Sequence
from typing_extensions import TypedDict
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]- 功能:定义了一个状态对象,包含一个消息列表(messages),用于记录对话历史和代理的中间输出。
- 设计理念:add_messages 是一个 reducer 函数,确保状态更新时消息按顺序追加,保持上下文的完整性。
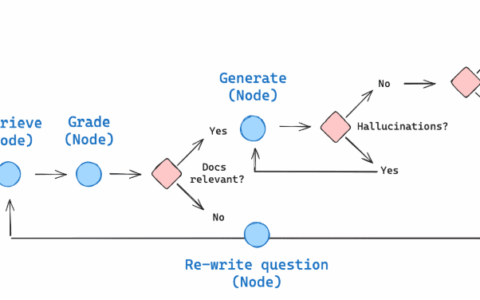
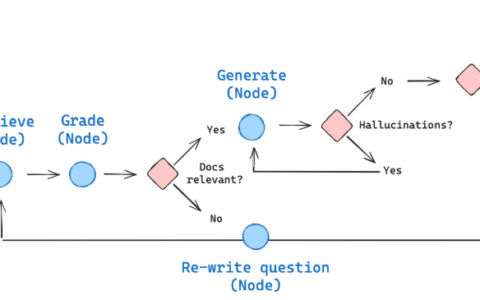
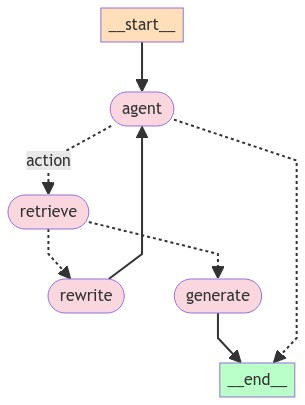
2.5 状态图构建
- 节点定义:
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import ToolNode
workflow = StateGraph(AgentState)
workflow.add_node("agent", agent)
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve)
workflow.add_node("rewrite", rewrite)
workflow.add_node("generate", generate)- 节点说明:
- agent:调用 LLM 决定是否需要检索或直接回答。
- retrieve:执行检索工具,获取相关文档。
- rewrite:重写用户查询以优化检索。
- generate:根据检索结果生成最终答案。
- 设计理念:每个节点代表一个独立的操作,模块化设计便于调试和扩展。
- 边定义:
workflow.add_edge(START, "agent")
workflow.add_conditional_edges(
"agent",
tools_condition,
{
"tools": "retrieve",
END: END,
},
)
workflow.add_edge("retrieve", "generate")
workflow.add_edge("rewrite", "agent")
workflow.add_edge("generate", END)- 功能:
- 从 START 开始,进入 agent 节点。
- agent 节点通过 tools_condition 函数决定是否调用检索工具(跳转到 retrieve)或直接结束。
- retrieve 完成后进入 generate。
- 如果需要重写查询(rewrite),则返回 agent 重新决策。
- 设计理念:条件边(conditional edges)实现了动态路由,体现了 Agentic RAG 的核心——根据上下文动态调整流程。
2.6 核心函数
- 代理调用(agent):
def agent(state):
print("---CALL AGENT---")
messages = state["messages"]
model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4-turbo")
model = model.bind_tools(tools)
response = model.invoke(messages)
return {"messages": [response]}- 功能:使用 GPT-4 Turbo 作为推理引擎,绑定检索工具,决定是否需要检索。
- 设计理念:通过工具绑定,LLM 可以输出工具调用指令,增强了代理的决策能力。
- 查询重写(rewrite):
def rewrite(state):
print("---TRANSFORM QUERY---")
messages = state["messages"]
question = messages[0].content
msg = [HumanMessage(content=f"""
Look at the input and try to reason about the underlying semantic intent / meaning.
""")]
model = ChatOpenAI(temperature=0, streaming=True, model="gpt-4-turbo")
response = model.invoke(msg)
return {"messages": [response]}- 功能:分析用户查询的语义意图,重写为更适合检索的版本。
- 设计理念:通过语义优化提高检索质量,适用于复杂或模糊的查询。
- 答案生成(generate):
def generate(state):
print("---GENERATE---")
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, streaming=True)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = prompt | llm | StrOutputParser()
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}- 功能:使用 RAG 提示模板(rlm/rag-prompt)和 GPT-3.5 Turbo 生成最终答案。
- 设计理念:RAG 链(rag_chain)将检索到的文档和用户问题结合,生成上下文相关的答案。
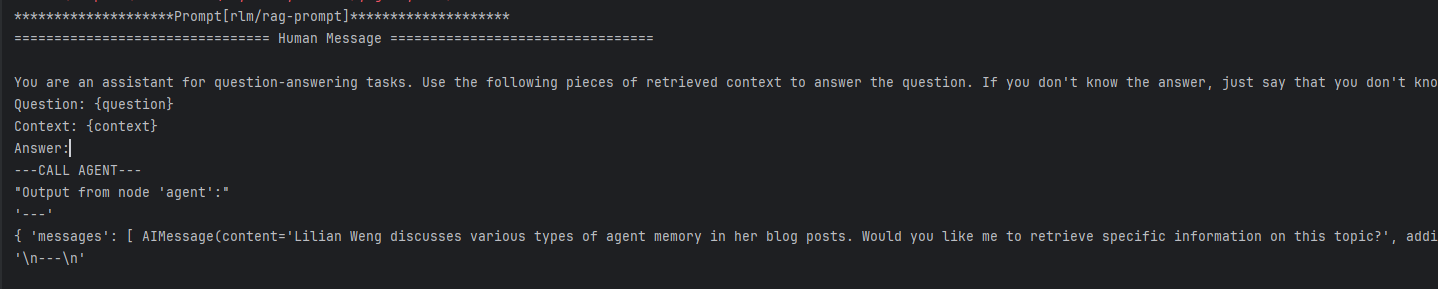
2.7 执行流程
- 编译和运行:
app = workflow.compile()
inputs = {"messages": [HumanMessage(content="What are the types of agent memory?")]}
for output in app.stream(inputs):
for key, value in output.items():
print(f"Output from node '{key}':")
print("---")
print(value)
print("\n---\n")最终输出效果图
3. Agentic RAG 范式分析
3.1 核心理念
Agentic RAG 相较于传统 RAG 的最大区别在于引入了 动态决策 和 状态管理:
- 传统 RAG:直接检索文档并生成答案,流程固定。
- Agentic RAG:通过代理(Agent)动态决定是否需要检索、是否重写查询、如何生成答案,流程可循环和自适应。
- 工具集成:检索工具的引入让代理可以访问外部知识,增强了回答能力。
- 状态持久化:AgentState 记录了消息历史,支持上下文感知和多轮对话。
在开发 AI Agent 时,langgraph_agentic_rag 提供以下启发:
- 状态机思维:将复杂流程分解为状态和转换,使用状态图管理逻辑,适合需要多步推理的场景。
- 工具化设计:将外部资源(如数据库、API)封装为工具,增强代理的扩展性。
如果在实际项目中应用,可以参考以下步骤:
- 定义业务需求:明确 Agent 需要解决的问题(如客服、研究助手)。
所有源代码
暂时无法在飞书文档外展示此内容
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9591