1. Self-RAG 范式概述
langgraph_self_rag 示例展示了一个 Self-RAG(Self-Reflective Retrieval-Augmented Generation) 工作流程,使用 LangGraph 实现。与传统 RAG 不同,Self-RAG 引入了自反思机制,通过动态评估生成结果和检索文档的相关性来优化答案质量。相比 langgraph_crag_local(Corrective RAG),Self-RAG 更注重生成阶段的自校正,而非仅依赖文档检索的校正。
其核心范式可以总结为:
- 状态管理:通过 GraphState 管理问题、文档、生成结果等状态。
- 节点与边:将 Self-RAG 流程分解为检索、生成、评估和校正等节点,通过条件边控制动态流程。
- 自反思:通过 LLM 评估生成结果的质量和文档相关性,决定是否重新检索或调整生成。
- 本地化支持:支持本地 LLM 和嵌入模型,适合离线或隐私敏感场景。
2. LangGraph 中 Self-RAG 的实现逻辑
在 LangGraph 的 examples/rag/langgraph_self_rag.ipynb 示例中,Self-RAG 被实现为一个基于 状态图(StateGraph) 的工作流。
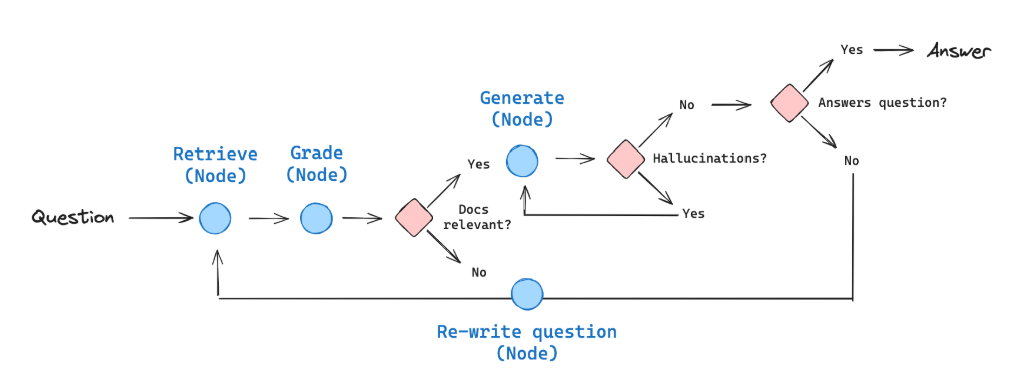
3. LangGraph Self-RAG 示例代码解析
以下结合代码片段说明其工作原理。
3.1 定义图状态(GraphState)
- 作用:GraphState 定义了工作流程的状态,贯穿所有节点。
- 字段解析:
- question:用户输入的问题。
- generation:LLM 生成的答案。
- documents:检索到的文档列表。
- is_relevant:文档是否与问题相关(布尔值)。
- needs_reflection:生成结果是否需要进一步反思或校正(布尔值)。
- steps:记录执行步骤,便于调试。
与 CRAG 的区别:
- 相比 langgraph_crag_local 的 search 字段(用于触发 Web 搜索),Self-RAG 使用 is_relevant 和 needs_reflection 更聚焦于文档和生成内容的质量评估。
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
question: str
generation: str
documents: List[str]
is_relevant: bool
needs_reflection: bool
steps: List[str]3.2 创建索引
示例中使用了 Chroma 向量数据库来存储文档嵌入,并通过 OpenAIEmbeddings 生成文档的向量表示。
在我们的Demo中我们用HuggingFaceEmbeddings代替了OpenAIEmbeddings
需要引用from langchain_huggingface import HuggingFaceEmbeddings。
同时要注意,下述代码中提供的几个URL可能失效或者无法访问,请修改成自己的。
这部分的代码和CRAG一致解释:
- 从指定 URL 加载博客文章并拆分为小块(每块 250 个 token)。
- 使用 OpenAI 的嵌入模型将文档转化为向量,存储在 Chroma 数据库中。
- 创建一个检索器,用于根据查询查找相关文档。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()3.3 定义工作流节点
CRAG 工作流包含以下节点,每个节点处理一个特定任务:
- 检索节点(retrieve):
功能:从向量数据库(如 Chroma)检索与问题相关的文档。
输入:用户问题 (state[“question”])。
输出:更新 documents 和 steps 字段。
与 CRAG 相似:两者都使用向量检索,但 Self-RAG 不立即触发 Web 搜索。
def retrieve(state):
""" Retrieve documents Args: state (dict): The current graph state Returns: state (dict): New key added to state, documents, that contains retrieved documents """print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
- 文档评分节点(gradeDocuments):
功能:使用 LLM 评估检索到的文档是否与问题相关。
逻辑:
- 对每个文档调用 LLM,生成相关性判断(relevant 或 irrelevant)。
- 保留相关文档,丢弃不相关文档。
- 设置 is_relevant 字段,表示是否有相关文档。
输出:更新 documents、is_relevant 和 steps。
与 CRAG 的区别:CRAG 使用 search 字段触发 Web 搜索,而 Self-RAG 使用 is_relevant 决定是否继续生成或调整流程。
def grade_documents(state):
""" Determines whether the retrieved documents are relevant to the question. Args: state (dict): The current graph state Returns: state (dict): Updates documents key with only filtered relevant documents """print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}- 生成节点(generate):
功能:根据检索到的文档和问题生成答案。
逻辑:使用预定义的 RAG 提示模板调用 LLM。
输出:更新 generation 和 steps。
与 CRAG 相似:生成逻辑类似,但 Self-RAG 会在后续节点评估生成质量。
def generate(state):
""" Generate answer Args: state (dict): The current graph state Returns: state (dict): New key added to state, generation, that contains LLM generation """print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
- reflect_on_generation(生成结果反思):
功能:使用 LLM 评估生成结果的质量,检查是否包含幻觉或与文档不一致。
逻辑:
- LLM 比较生成结果与文档内容,判断是否需要校正(needs_reflection = True)。
- 评估可能基于预定义提示,如“生成内容是否准确引用了文档?”。
输出:更新 needs_reflection 和 steps。
与 CRAG 的区别:CRAG 没有生成结果反思节点,Self-RAG 的自反思是其核心特性。
def reflect_on_generation(state):
question = state["question"]
documents = state["documents"]
generation = state["generation"]
result = llm.invoke([...]) # 使用 LLM 评估生成结果
needs_reflection = result.content.lower() == "needs_reflection"
return {
"needs_reflection": needs_reflection,
"steps": state["steps"] + ["reflect_on_generation"]
}- 决定生成
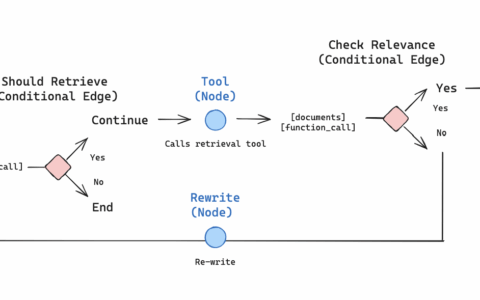
如果 is_relevant = True,进入生成阶段。
否则,重新检索文档。
def decide_to_generate(state):
""" Determines whether to generate an answer, or re-generate a question. Args: state (dict): The current graph state Returns: str: Binary decision for next node to call """print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"3.4 构建图结构
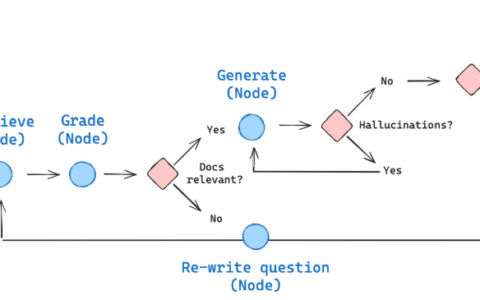
流程逻辑:
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()Self-RAG 设计体现了以下关键范式:
3.1 模块化与状态管理
- 模块化:每个节点(retrieve、grade_documents、generate、reflect_on_generation)独立,便于维护和扩展。
- 状态管理:GraphState 确保状态在节点间一致传递,is_relevant 和 needs_reflection 字段支持动态决策。
3.2 自反思机制
- 文档评估:通过 grade_documents 过滤无关文档,确保生成基于高质量信息。
- 生成反思:reflect_on_generation 节点是 Self-RAG 的核心,使用 LLM 评估生成结果的准确性和一致性,减少幻觉。
- 动态调整:通过条件边支持循环(如重新检索或重新生成),实现自校正。
4. 与 langgraph_crag_local 的对比
表格 还在加载中,请等待加载完成后再尝试复制
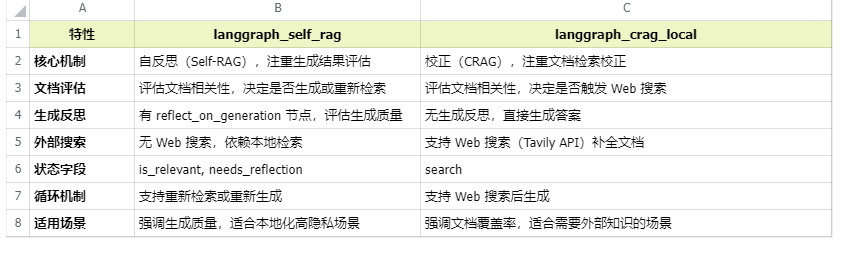
附上全部源代码
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9596