1. 什么是 Corrective RAG Local?
Corrective RAG (CRAG)Local LLM和 CRAG大致相同,唯一的不同点在于特别使用了本地 LLM(如 Llama3 或 Mistral)和本地嵌入模型(如 Nomic 嵌入),适合离线或隐私敏感场景。
其核心范式可以总结为:
- 状态管理:通过 GraphState 管理整个工作流程的状态(如问题、文档、生成结果等)。
- 节点与边:将 CRAG 流程分解为多个节点(检索、评估、生成等),通过边和条件边控制流程。
- 自校正:通过文档相关性评估决定是否进行 Web 搜索补充,并对生成结果进行检查以避免幻觉。
- 本地化:使用本地 LLM 和嵌入模型,减少对云端 API 的依赖。

2. LangGraph 中 CRAG 的实现逻辑
在 LangGraph 的 examples/rag/langgraph_crag_local.ipynb 示例中,CRAG 被实现为一个基于 状态图(StateGraph) 的工作流。
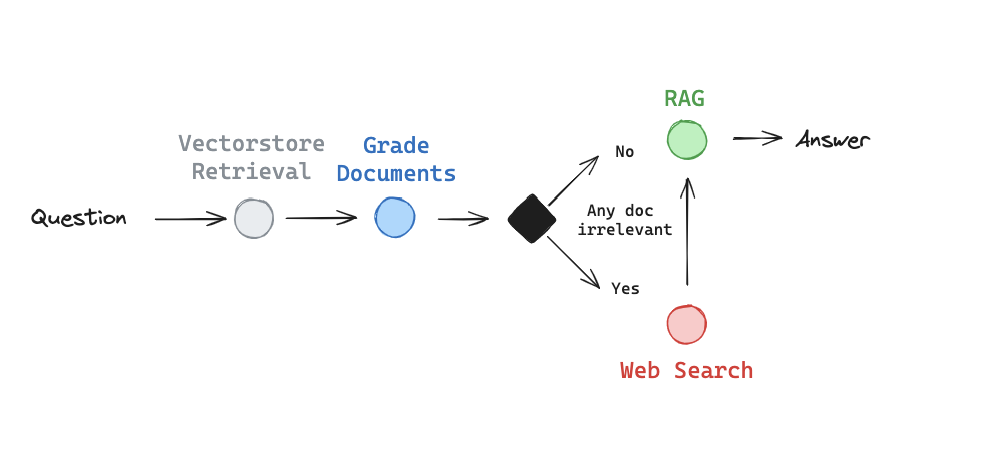
下图是之前的,我们可以做个对比。
从我个人的理解,就只是LLM替换成了本地模型。并没有看到和CRAG比较明显的内容。当然涉及到Langsmith部分的测试和评估我并没有细看,因为那部分我们的体系目前并没有使用到。

CRAG 的工作流包括以下关键步骤:
- 检索文档(Retrieve):从向量数据库中检索与用户查询相关的文档。
- 评估文档相关性(Grade Documents):对检索到的文档进行相关性评分,判断是否满足生成要求。
- 决定是否生成(Decide to Generate):根据文档评分决定是直接生成答案、触发 Web 搜索,还是重写查询。
- 重写查询(Transform Query):如果文档不相关,优化查询以便进行更有效的检索。
- Web 搜索(Web Search):当检索到的文档不足以回答问题时,使用外部搜索补充信息。
- 生成答案(Generate):基于最终的文档集合生成答案。
3. LangGraph CRAG LocalLLM示例代码解析
以下结合代码片段说明其工作原理。
3.1 定义图状态(GraphState)
作用:GraphState 是一个类型化的字典,定义了工作流程中需要传递和更新的状态。
字段解析:
- question:用户输入的问题。
- generation:LLM 生成的答案。
- search:是否需要 Web 搜索(例如 “yes” 或 “no”)。
- documents:检索到的文档列表。
- steps:记录工作流程的执行步骤(用于调试或跟踪)。
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
search: whether to add search
documents: list of documents
"""
question: str
generation: str
search: str
documents: List[str]
steps: List[str]解释:这个状态类定义了工作流中每个节点共享和更新的数据结构,确保信息在节点间传递。
3.2 创建索引
示例中使用了 Chroma 向量数据库来存储文档嵌入,并通过 OpenAIEmbeddings 生成文档的向量表示。
在我们的Demo中我们用HuggingFaceEmbeddings代替了OpenAIEmbeddings
需要引用from langchain_huggingface import HuggingFaceEmbeddings。
同时要注意,下述代码中提供的几个URL可能失效或者无法访问,请修改成自己的。 解释:
- 从指定 URL 加载博客文章并拆分为小块(每块 250 个 token)。
- 使用 OpenAI 的嵌入模型将文档转化为向量,存储在 Chroma 数据库中。
- 创建一个检索器,用于根据查询查找相关文档。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()3.3 定义工作流节点
CRAG 工作流包含以下节点,每个节点处理一个特定任务:
Define Tools
### Retrieval Grader
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
from langchain_mistralai.chat_models import ChatMistralAI
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""You are a teacher grading a quiz. You will be given:
1/ a QUESTION
2/ A FACT provided by the student
You are grading RELEVANCE RECALL:
A score of 1 means that ANY of the statements in the FACT are relevant to the QUESTION.
A score of 0 means that NONE of the statements in the FACT are relevant to the QUESTION.
1 is the highest (best) score. 0 is the lowest score you can give.
Explain your reasoning in a step-by-step manner. Ensure your reasoning and conclusion are correct.
Avoid simply stating the correct answer at the outset.
Question: {question} \n
Fact: \n\n {documents} \n\n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no premable or explanation.
""",
input_variables=["question", "documents"],
)
retrieval_grader = prompt | llm | JsonOutputParser()
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "documents": doc_txt}))
### Generate
from langchain_core.output_parsers import StrOutputParser
# Prompt
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following documents to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Documents: {documents}
Answer:
""",
input_variables=["question", "documents"],
)
# LLM
llm = ChatOllama(model=local_llm, temperature=0)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"documents": docs, "question": question})
print(generation)- Create the graph
from typing import List
from typing_extensions import TypedDict
from IPython.display import Image, display
from langchain.schema import Document
from langgraph.graph import START, END, StateGraph
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
search: whether to add search
documents: list of documents
"""
question: str
generation: str
search: str
documents: List[str]
steps: List[str]
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
question = state["question"]
documents = retriever.invoke(question)
steps = state["steps"]
steps.append("retrieve_documents")
return {"documents": documents, "question": question, "steps": steps}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
question = state["question"]
documents = state["documents"]
generation = rag_chain.invoke({"documents": documents, "question": question})
steps = state["steps"]
steps.append("generate_answer")
return {
"documents": documents,
"question": question,
"generation": generation,
"steps": steps,
}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
question = state["question"]
documents = state["documents"]
steps = state["steps"]
steps.append("grade_document_retrieval")
filtered_docs = []
search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "documents": d.page_content}
)
grade = score["score"]
if grade == "yes":
filtered_docs.append(d)
else:
search = "Yes"
continue
return {
"documents": filtered_docs,
"question": question,
"search": search,
"steps": steps,
}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
question = state["question"]
documents = state.get("documents", [])
steps = state["steps"]
steps.append("web_search")
web_results = web_search_tool.invoke({"query": question})
documents.extend(
[
Document(page_content=d["content"], metadata={"url": d["url"]})
for d in web_results
]
)
return {"documents": documents, "question": question, "steps": steps}
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
search = state["search"]
if search == "Yes":
return "search"
else:
return "generate"
# Graph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("web_search", web_search) # web search
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"search": "web_search",
"generate": "generate",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("generate", END)
custom_graph = workflow.compile()
display(Image(custom_graph.get_graph(xray=True).draw_mermaid_png()))import uuid
def predict_custom_agent_local_answer(example: dict):
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
state_dict = custom_graph.invoke(
{"question": example["input"], "steps": []}, config
)
return {"response": state_dict["generation"], "steps": state_dict["steps"]}
example = {"input": "What are the types of agent memory?"}
response = predict_custom_agent_local_answer(example)
response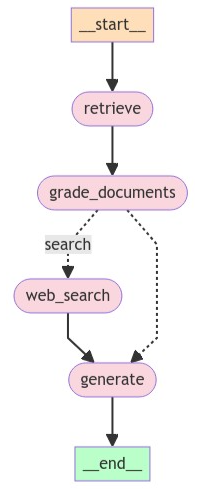
. 关键范式分析
langgraph_crag_local 的设计体现了以下关键范式:
如果你已经熟悉了CRAG,可以只看绿色高亮内容即可。
3.1 模块化与状态管理
- 模块化:每个节点(retrieve、grade_documents 等)是一个独立的功能模块,便于维护和扩展。例如,可以轻松添加知识精炼节点。
- 状态管理:GraphState 作为全局状态,贯穿整个流程,确保数据在节点间一致传递。TypedDict 提供类型安全性,减少错误。
3.2 自校正机制
- 文档评估:通过 LLM 评估文档相关性,过滤无关信息,降低生成错误答案的风险。
- Web 搜索补充:当本地检索不足时,动态触发 Web 搜索,增强信息覆盖率。
- 简化知识精炼:示例中跳过了 CRAG 论文中的知识精炼步骤(将文档分割为知识片段并逐个评估),但提供了扩展点,允许用户添加该功能。
3.3 本地化实现
- 本地 LLM:使用 Ollama 提供的模型(如 Llama3 或 Mistral),支持离线运行,适合隐私敏感场景。
- 本地嵌入:使用 Nomic 的 GPT4AllEmbeddings 或其他本地嵌入模型,减少对云端 API 的依赖。
- 向量存储:使用 Chroma 作为本地向量数据库,存储文档嵌入,便于快速检索。
3.4 LangGraph 的灵活性
- 图结构:LangGraph 的节点-边模型允许灵活定义复杂工作流程,支持条件分支和循环。
- 条件边:通过 add_conditional_edges,实现动态路由(如根据文档相关性决定是否搜索)。
- 可扩展性:可以轻松添加新节点(如查询重写、生成评估)或修改边逻辑。
4. 优缺点分析
4.1 优点
- 准确性提升:通过文档评估和 Web 搜索,CRAG 有效减少了无关或错误信息的干扰。
- 本地化支持:完全本地化的 LLM 和嵌入模型适合隐私敏感或离线场景。
- 灵活性:LangGraph 的图结构支持复杂工作流程的自定义和扩展。
- 模块化设计:节点独立,便于维护和升级。
4.2 缺点
- 性能开销:本地 LLM 和嵌入模型可能需要较高计算资源,尤其在低端设备上。
- 简化实现:跳过了知识精炼步骤,可能在某些复杂场景下效果受限。
- Web 搜索依赖:虽然是补充机制,但仍需 Tavily API 密钥,增加了外部依赖。
- 评估一致性:LLM 作为文档评估器可能存在主观性,评分一致性需进一步优化。
附上全部源代码
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9575