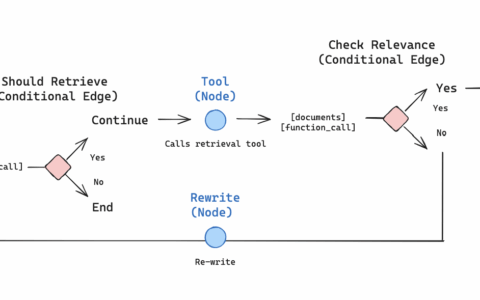
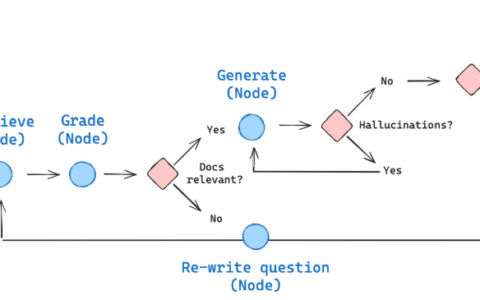
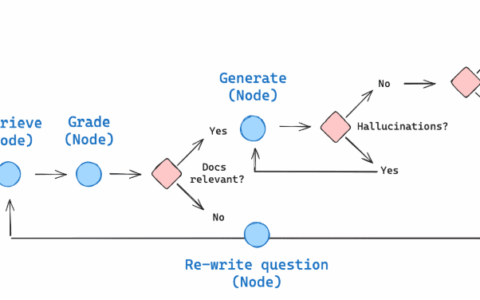
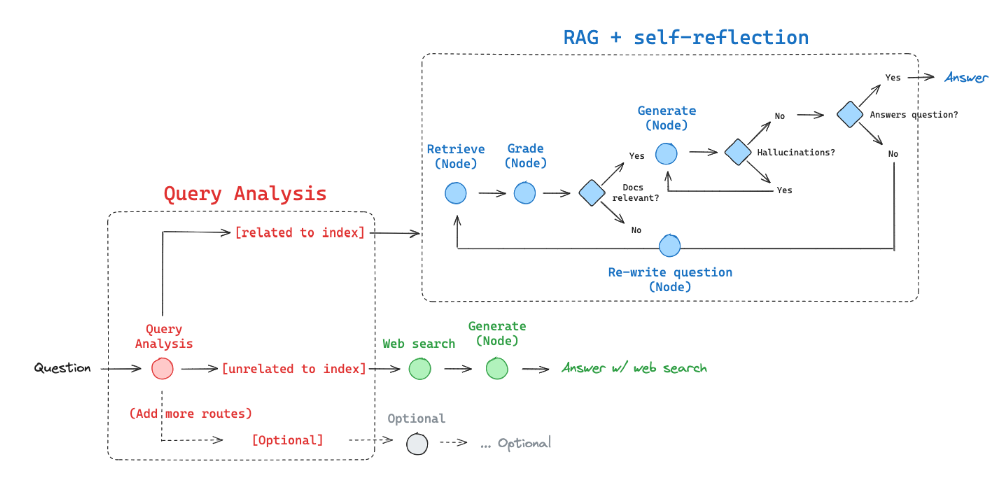
Adaptive RAG 是一种 RAG 策略,它将 (1) 查询分析与 (2) 主动/自我纠正 RAG 结合在一起。通过动态调整检索和生成策略来优化答案质量。
参考论文:https://arxiv.org/abs/2403.14403
重要提示:
- 后续忽略单独分析langgraph_adaptive_rag_local,因为它和本文的区别就只是在于LLM用了本地Ollama的。
- 同时也一笔带过Cohere的范式,它用了cohere来代替常规的OpenAI为代表的典型LLM,如下面一句。
llm = ChatCohere(model=”command-r”, temperature=0)
安装依赖
pip install -U langchain_community tiktoken langchain-openai langchain-cohere langchainhub chromadb langchain langgraph tavily-python
2 上来还是建立索引,
要注意的是这次的切片大小500,(较大的 chunk_size 适合百科类长文本)
### Build Index
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
### from langchain_cohere import CohereEmbeddings
# Set embeddings
embd = OpenAIEmbeddings()
# Docs to index
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# Load
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
# Split
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=500, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorstore
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=embd,
)
retriever = vectorstore.as_retriever()研究了RAG范式的内容后,有很多代码是雷同的,就不复制了。
只挑选有特点的代码端,做重点解释分析。
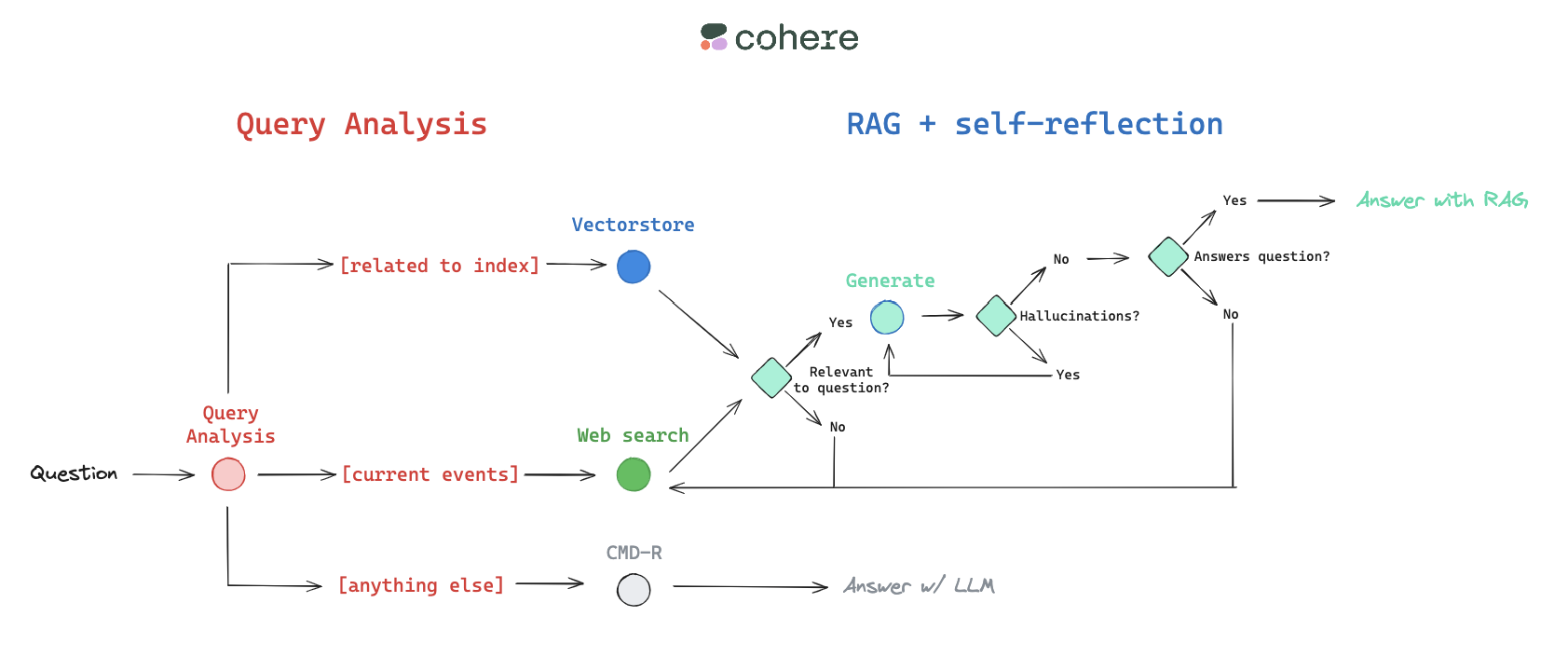
RouteQuery,路由查询,让用户的查询找一个最相关的数据源。这里是向量数据库中还是网页查询。
### Router
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""datasource: Literal["vectorstore", "web_search"] = Field(
...,
description="Given a user question choose to route it to web search or a vectorstore.",
)
structured_llm_router = llm.with_structured_output(RouteQuery)
# Prompt
system = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore contains documents related to agents, prompt engineering, and adversarial attacks.
Use the vectorstore for questions on these topics. Otherwise, use web-search."""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
question_router = route_prompt | structured_llm_router
print(
question_router.invoke(
{"question": "Who will the Bears draft first in the NFL draft?"}
)
)
print(question_router.invoke({"question": "What are the types of agent memory?"}))GradeDocuments
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
prompt = PromptTemplate(
template="""You are a grader assessing the relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n
If the document contains information relevant to the question, score it as 'yes'. Otherwise, score it as 'no'.
Provide the binary score as a string."""
)
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = []
for d in documents:
score = structured_llm_grader.invoke({"question": question, "document": d.page_content})
if score.binary_score == "yes":
filtered_docs.append(d)
return {"documents": filtered_docs, "question": question}功能:定义了一个提示模板,指导 LLM 如何评估文档相关性。
输入:
- {document}:检索到的文档内容。
- {question}:用户的问题。
输出要求:LLM 必须返回 “yes” 或 “no”,表示文档是否相关。
3 Adaptive RAG 范式分析
3.1 核心理念
Adaptive RAG 相较于传统 RAG 和 Agentic RAG 的最大区别在于 动态评估和调整策略:
- 传统 RAG:固定流程(检索 → 生成),缺乏灵活性。
- Agentic RAG:引入代理决策,但主要聚焦于是否检索或重写查询。
- Adaptive RAG:通过评估检索结果的质量(相关性)和查询需求,动态选择最佳知识源(本地或 Web),并优化生成过程。
3.2 关键设计模式
- 模块化:节点(如 retrieve、grade_documents、web_search)职责单一,便于维护和扩展。
- 条件决策:decide_to_generate 函数实现自适应路由,体现了动态调整的核心。
- 文档评分机制:使用结构化输出(GradeDocuments)和 LLM 进行语义评估,显著提高检索精度。
4. 可能的优化建议
- 增强评分机制:优化 grade_documents 的提示,加入多维度评估(如信息完整性、时效性)。
- 支持多模态数据:扩展 WikipediaLoader 或添加图像、表格解析器,处理非文本数据。
- 查询重写:引入查询重写节点(如 Agentic RAG 的 rewrite),优化复杂或模糊查询的检索效果。
- 多轮对话:扩展 GraphState,记录对话历史,支持上下文感知的交互。
与实际开发的启发
- 自适应设计:通过评分和条件路由实现动态策略,适合处理多样化或不确定的用户需求。
- 质量优先:引入评分机制(如文档相关性)优化输出,适用于高精度场景(如知识问答)。
- 多源整合:结合本地和外部数据源(如 Web 搜索),增强知识覆盖能力。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9586