STORM范式概述
STORM(Structured Topic-based Outline and Research Machine)是一个由大型语言模型(LLM)驱动的自动化研究与内容生成框架,最初由Stanford OVAL实验室提出,用于从零开始生成类似维基百科的文章。在LangGraph的实现中,STORM被重构为一个基于LangGraph的多智能体工作流,结合LangChain生态的工具,强调结构化研究和内容生成。
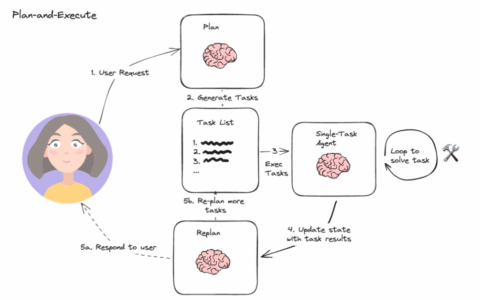
STORM 主要包含以下几个阶段:
生成初步提纲 + 调研相关主题
识别独特视角
“访谈主题专家”
完善提纲(参考文献)
撰写章节,然后撰写文章
专家访谈阶段由角色扮演文章作者和研究专家进行。“专家”能够查询外部知识并回答尖锐问题,并将引用的来源保存到向量存储中,以便后续的完善阶段能够合成完整的文章。
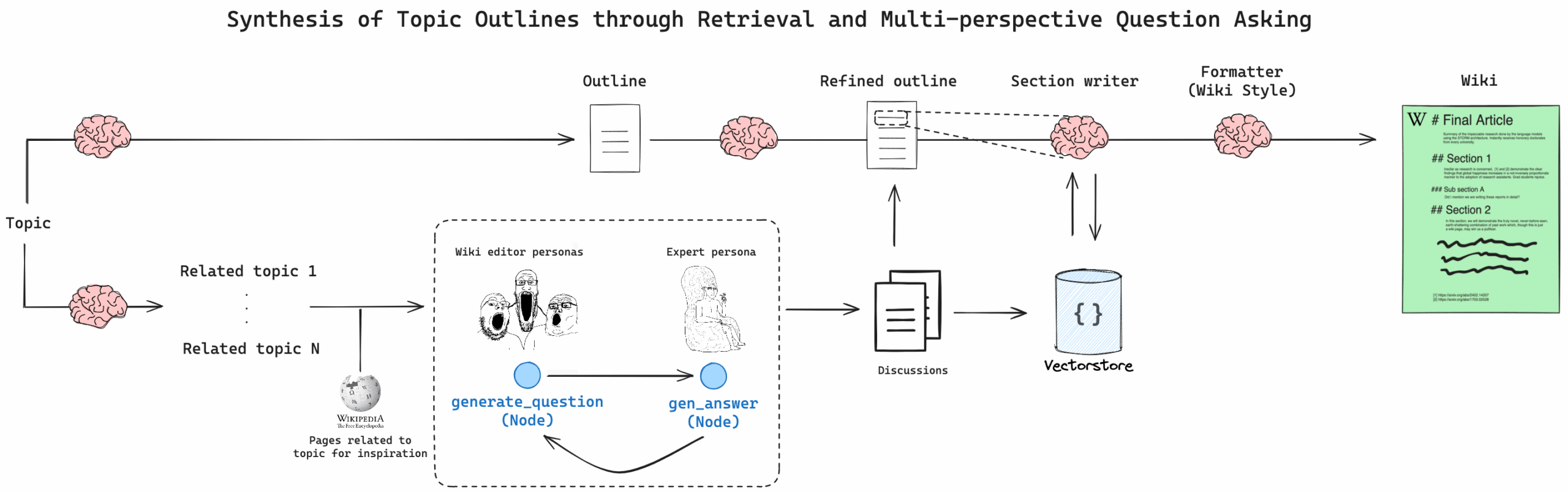
STORM范式是一种多智能体协作的典型实现,核心目标是通过分解任务、调用外部工具和迭代优化,生成高质量、带引用的研究文章。其设计理念可以总结为:
- 任务分解:将复杂的研究和写作任务分解为多个子任务(如主题探索、大纲生成、内容撰写)。
- 多智能体协作:通过LangGraph的状态图(StateGraph)定义不同智能体角色(如研究员、写作者),实现协作。
- 外部工具集成:利用搜索引擎(如Tavily)获取实时信息,增强内容的全面性和准确性。
- 迭代优化:通过多轮对话和反馈,逐步完善大纲和文章内容。

1.2 STORM范式的核心组件
- 主题探索(Topic Exploration):
- 通过与LLM对话,生成与主题相关的关键问题,扩展研究方向。
- 调用外部搜索引擎(如Tavily)收集参考资料。
- 大纲生成(Outline Generation):
- 基于主题和搜索结果,生成结构化的大纲,包含主要章节和子主题。
- 通过多角度提问,确保大纲覆盖主题的多个方面。
- 内容生成(Content Generation):
- 根据大纲,逐章节生成文章内容,并为每部分添加引用。
- 通过LLM的润色功能,提升内容的逻辑性和可读性。
- 多智能体工作流:
- 使用LangGraph的状态图管理不同智能体的协作,例如“研究员”负责信息收集,“写作者”负责内容生成。
- 状态图维护全局状态(如主题、搜索结果、大纲、文章),确保任务连贯性。
1.3 STORM范式的AI Agent特性
- 多智能体架构:通过LangGraph的StateGraph,定义多个智能体角色,每个角色专注于特定任务(如搜索、生成),实现协作。
- 状态管理:LangGraph的状态图维护任务的全局状态(如当前大纲、文章内容),支持动态更新和条件分支。
- 工具调用:通过LangChain的工具调用机制,集成外部API(如Tavily搜索),增强Agent的环境感知能力。
- 迭代推理:通过多轮对话和反馈,STORM模拟专家讨论,逐步优化输出,类似于Agent的自我反思(self-reflection)。
- 模块化设计:LangGraph的工作流允许开发者自定义智能体、工具或Prompt,适合不同应用场景。
1.4 STORM范式与AI Agent开发的关联
- 多智能体协作:通过定义不同角色(如研究员、写作者),实现复杂任务的分工协作,适合构建分布式Agent系统。
- 状态驱动的工作流:LangGraph的状态图提供了一种声明式的工作流定义方式,开发者可以用类似方法管理Agent的状态和决策。
- 工具集成:STORM通过Tavily搜索API获取实时数据,开发者可扩展为更多工具(如数据库、知识图谱)以增强功能。
- Prompt工程:STORM依赖精心设计的Prompt模板,开发者可以借鉴其结构化Prompt设计,优化Agent的输出质量。
- 可扩展性:LangGraph的模块化设计允许开发者替换LLM、工具或工作流逻辑,适配特定需求。
以下开始进行主要的源代码解释
数据结构定义
STORM 的工作流需要维护一个状态对象,用于在节点间传递数据。代码定义了 StormState 作为状态类型:
from typing import TypedDict, List, Dict, Optional
class StormState(TypedDict):
topic: str
initial_research: Dict
perspectives: List[Dict]
questions: List[Dict]
search_results: List[Dict]
outline: Dict
article: Dict- topic: 输入的主题(如“人工智能的历史”)。
- initial_research: 初步研究结果,包含主题概述和背景信息。
- perspectives: 主题的多视角列表(如历史、技术、伦理)。
- questions: 为每个视角生成的提问,用于指导检索。
- search_results: 检索工具返回的相关信息。
- outline: 文章大纲,包含章节和子章节。
- article: 最终生成的文章内容。
这种状态设计符合 LangGraph 的状态图理念,允许节点更新和传递复杂的数据结构。
2.3 核心组件与工作流
STORM 的实现分为多个节点,每个节点负责工作流的一个阶段。以下是主要节点的分析:
2.3.1 初步研究(Initial Research)
第一步是理解输入主题并生成初步研究。代码定义了一个 initial_research 节点:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o", temperature=0.7)
initial_research_prompt = ChatPromptTemplate.from_template(
"""You are a research assistant tasked with providing a brief overview of {topic}.
Provide a concise summary (100-150 words) and identify 3-5 key perspectives for further exploration.
Format the output as:
<summary>...</summary>
<perspectives>...</perspectives>
"""
)
initial_research_chain = initial_research_prompt | llm | StrOutputParser()
def initial_research(state: StormState):
topic = state["topic"]
result = initial_research_chain.invoke({"topic": topic})
summary = re.search(r"<summary>(.*?)</summary>", result, re.DOTALL).group(1).strip()
perspectives = re.search(r"<perspectives>(.*?)</perspectives>", result, re.DOTALL).group(1).strip()
return {
"initial_research": {"summary": summary},
"perspectives": [{"name": p.strip()} for p in perspectives.split("\n") if p.strip()]
}- Prompt: 要求 LLM 生成主题的简要概述(100-150 字)和 3-5 个关键视角。
- Output Parser: 使用正则表达式提取 <summary> 和 <perspectives>。
- Node: initial_research 更新状态中的 initial_research 和 perspectives 字段。
2.3.2 视角提问(Generate Questions)
第二步是为每个视角生成具体问题,指导后续检索。代码定义了一个 generate_questions 节点:
question_prompt = ChatPromptTemplate.from_template(
"""Given the topic '{topic}' and perspective '{perspective}',
generate 2-3 specific questions to guide research.
Format the output as:
<questions>...</questions>
"""
)
question_chain = question_prompt | llm | StrOutputParser()
def generate_questions(state: StormState):
topic = state["topic"]
perspectives = state["perspectives"]
questions = []
for perspective in perspectives:
result = question_chain.invoke({"topic": topic, "perspective": perspective["name"]})
q_list = re.search(r"<questions>(.*?)</questions>", result, re.DOTALL).group(1).strip()
questions.append({"perspective": perspective["name"], "questions": q_list.split("\n")})
return {"questions": questions}- Prompt: 为每个视角生成 2-3 个具体问题。
- Node: generate_questions 遍历视角,生成问题列表,更新状态中的 questions 字段。
2.3.3 信息检索(Search)
第三步是使用检索工具获取相关信息。代码集成了维基百科作为检索工具:
from langchain_community.utilities import WikipediaAPIWrapper
wikipedia = WikipediaAPIWrapper()
def search(state: StormState):
questions = state["questions"]
search_results = []
for q_group in questions:
perspective = q_group["perspective"]
for question in q_group["questions"]:
try:
result = wikipedia.run(question)
search_results.append({"perspective": perspective, "question": question, "result": result})
except:
search_results.append({"perspective": perspective, "question": question, "result": "No results found"})
return {"search_results": search_results}- Tool: 使用 WikipediaAPIWrapper 执行检索,基于生成的提问。
- Node: search 遍历每个视角的问题,调用维基百科 API,收集结果并更新状态中的 search_results。
- Error Handling: 简单处理检索失败的情况,返回“No results found”。
2.3.4 大纲生成(Generate Outline)
第四步是基于检索结果和初步研究生成文章大纲:
outline_prompt = ChatPromptTemplate.from_template(
"""Given the topic '{topic}', initial research, perspectives, and search results,
generate a structured article outline.
Format the output as:
<outline>
<section>...</section>
<section>...</section>
</outline>
"""
)
outline_chain = outline_prompt | llm | StrOutputParser()
def generate_outline(state: StormState):
topic = state["topic"]
initial_research = state["initial_research"]
perspectives = state["perspectives"]
search_results = state["search_results"]
result = outline_chain.invoke({
"topic": topic,
"initial_research": initial_research,
"perspectives": perspectives,
"search_results": search_results
})
outline = re.search(r"<outline>(.*?)</outline>", result, re.DOTALL).group(1).strip()
return {"outline": {"sections": outline.split("\n")}}- Prompt: 要求 LLM 整合所有信息,生成结构化大纲。
- Node: generate_outline 更新状态中的 outline 字段,包含章节列表。
2.3.5 文章生成(Generate Article)
最后一步是生成完整文章:
article_prompt = ChatPromptTemplate.from_template(
"""Given the topic '{topic}', outline, and research data,
write a detailed article (300-500 words).
Format the output as:
<article>...</article>
"""
)
article_chain = article_prompt | llm | StrOutputParser()
def generate_article(state: StormState):
topic = state["topic"]
outline = state["outline"]
initial_research = state["initial_research"]
search_results = state["search_results"]
result = article_chain.invoke({
"topic": topic,
"outline": outline,
"initial_research": initial_research,
"search_results": search_results
})
article = re.search(r"<article>(.*?)</article>", result, re.DOTALL).group(1).strip()
return {"article": {"content": article}}- Prompt: 要求 LLM 基于大纲和研究数据生成文章。
- Node: generate_article 更新状态中的 article 字段。
2.4 状态图构建
LangGraph 的核心是 StateGraph,代码将其用于协调上述步骤:
from langgraph.graph import StateGraph, END
workflow = StateGraph(StormState)
workflow.add_node("initial_research", initial_research)
workflow.add_node("generate_questions", generate_questions)
workflow.add_node("search", search)
workflow.add_node("generate_outline", generate_outline)
workflow.add_node("generate_article", generate_article)
workflow.set_entry_point("initial_research")
workflow.add_edge("initial_research", "generate_questions")
workflow.add_edge("generate_questions", "search")
workflow.add_edge("search", "generate_outline")
workflow.add_edge("generate_outline", "generate_article")
workflow.add_edge("generate_article", END)
graph = workflow.compile()- Nodes: 五个节点分别对应初步研究、提问生成、检索、大纲生成和文章生成。
- Edges: 定义了线性执行顺序:initial_research -> generate_questions -> search -> generate_outline -> generate_article -> END.
- Compilation: workflow.compile() 生成可执行的 LangGraph 图。
2.5 示例运行
代码提供了一个示例主题并运行工作流:
state = {"topic": "The History of Artificial Intelligence"}
result = graph.invoke(state)
print("Outline:")
for section in result["outline"]["sections"]:
print(section)
print("\nArticle:")
print(result["article"]["content"])- Input: 主题为“The History of Artificial Intelligence”。
- Output: 最终状态包含初步研究、视角、提问、检索结果、大纲和文章。
示例输出可能如下(具体取决于 LLM 和检索结果):
Outline:
- Introduction
- Early Concepts and Foundations
- The AI Boom and Modern Developments
- Ethical and Societal Impacts
Article:
The history of artificial intelligence (AI) spans decades, evolving from theoretical concepts to transformative technologies. ...Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9644