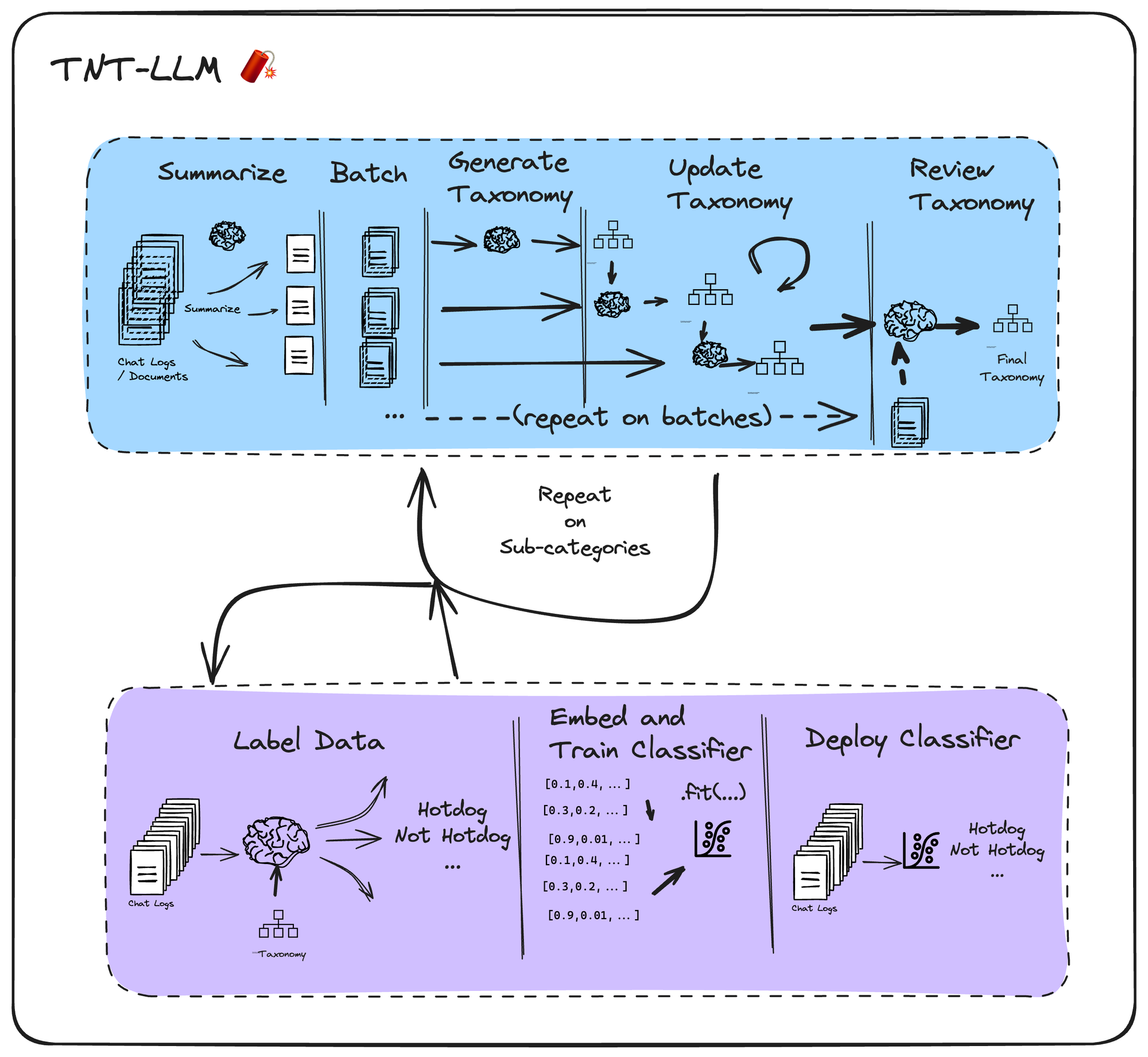
TNT-LLM(Taxonomy-augmented LLM)是由 Microsoft 为其 Bing Copilot 应用开发的一种分类系统,旨在从原始对话日志中生成可解释的用户意图分类体系(taxonomy),并利用该体系对日志进行标注,进而训练高效的分类器(如基于嵌入的逻辑回归分类器)。该范式特别适用于处理大规模对话数据,生成结构化的意图分类,并支持下游任务,如用户行为分析、模型优化等。
在 LangGraph 中,TNT-LLM 被实现为一个多步骤的工作流,利用 LangGraph 的状态图(StateGraph)来协调多个 LLM 调用和数据处理步骤。LangGraph 的核心优势在于其支持状态管理、循环、并行处理和持久化,特别适合实现 TNT-LLM 这样复杂的多阶段任务。
TNT-LLM 的核心流程包括以下五个步骤(在 LangGraph 中主要聚焦于前三个步骤,即分类体系生成):
- Summarize chat logs: 使用低成本的 LLM(如 Claude-3-Haiku)对对话日志进行批量摘要,生成简洁的摘要和解释。
- Generate candidate taxonomy: 根据摘要生成初步的分类体系(candidate taxonomy),通常以聚类形式表示。
- Refine taxonomy: 迭代优化分类体系,合并相似类别,剔除冗余,确保分类体系的简洁性和可解释性。
- Label logs: 使用生成的分类体系对原始日志进行标注
- Train classifier: 基于标注数据训练分类器(如逻辑回归),用于生产环境中高效推理
数据结构定义
TNT-LLM 的工作流需要维护一个状态对象,用于在不同节点之间传递数据。代码定义了 TaxonomyGenerationState 作为状态类型:
from typing import TypedDict, List, Dict
class TaxonomyGenerationState(TypedDict):
documents: List[Dict]
summaries: List[Dict]
candidate_taxonomy: List[Dict]
taxonomy: List[Dict]- documents: 原始对话日志,包含 id 和 content 字段。
- summaries: 摘要数据,包含 summary 和 explanation 字段。
- candidate_taxonomy: 初步分类体系,包含类别描述和关键词。
- taxonomy: 最终优化后的分类体系。
这种状态设计符合 LangGraph 的状态图理念,允许节点在处理过程中更新和传递状态。

2.3 摘要生成(Summarize Chat Logs)
摘要生成是 TNT-LLM 的第一步,旨在将冗长的对话日志压缩为简洁的摘要和解释。代码使用 LangChainRunnable 组件和 Anthropic 的 Claude-3-Haiku 模型实现:
from langchain import hub
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableConfig, RunnableLambda, RunnablePassthrough
summary_prompt = hub.pull("wfh/tnt-llm-summary-generation").partial(
summary_length=20, explanation_length=30
)
def parse_summary(xml_string: str) -> dict:
summary_pattern = r"<summary>(.*?)</summary>"
explanation_pattern = r"<explanation>(.*?)</explanation>"
summary_match = re.search(summary_pattern, xml_string, re.DOTALL)
explanation_match = re.search(explanation_pattern, xml_string, re.DOTALL)
summary = summary_match.group(1).strip() if summary_match else ""
explanation = explanation_match.group(1).strip() if explanation_match else ""
return {"summary": summary, "explanation": explanation}
summary_llm_chain = (
summary_prompt
| ChatAnthropic(model="claude-3-haiku-20240307")
| StrOutputParser()
).with_config(run_name="GenerateSummary")
summary_chain = summary_llm_chain | parse_summary- Prompt: 从 LangChain Hub 拉取预定义的 tnt-llm-summary-generation 提示,设置摘要长度为 20 字,解释长度为 30 字。
- LLM: 使用成本较低的 Claude-3-Haiku 模型,适合批量处理大规模数据。
- Output Parser: 使用正则表达式解析 LLM 返回的 XML 格式输出,提取 summary 和 explanation。
- Chain: 构建一个 LangChain 链,串联提示、LLM 和解析器。
摘要生成采用 map-reduce 模式,代码定义了一个 map_step 来并行处理文档:
def get_content(state: TaxonomyGenerationState):
docs = state["documents"]
return [{"content": doc["content"]} for doc in docs]
map_step = RunnablePassthrough.assign(
summaries=get_content
| RunnableLambda(func=summary_chain.batch, afunc=summary_chain.abatch)
)
def reduce_summaries(combined: dict) -> TaxonomyGenerationState:
summaries = combined["summaries"]
documents = combined["documents"]
return {
"documents": [
{
"id": doc["id"],
"content": doc["content"],
"summary": summ_info["summary"],
"explanation": summ_info["explanation"],
}
for doc, summ_info in zip(documents, summaries)
]
}- Map Step: get_content 提取文档内容,summary_chain.batch 并行调用 LLM 生成摘要。
- Reduce Step: reduce_summaries 将摘要和原始文档合并,更新状态中的 documents 字段。
2.4 候选分类体系生成(Generate Candidate Taxonomy)
第二步是基于摘要生成初步的分类体系。代码定义了一个 generate_taxonomy_chain:
taxonomy_prompt = hub.pull("wfh/tnt-llm-generate-taxonomy").partial(num_clusters=5)
generate_taxonomy_chain = (
taxonomy_prompt
| ChatAnthropic(model="claude-3-5-sonnet-latest")
| StrOutputParser()
).with_config(run_name="GenerateTaxonomy")
def parse_taxonomy(taxonomy_string: str) -> List[Dict]:
taxonomy = []
pattern = r"<category>\s*<name>(.*?)</name>\s*<description>(.*?)</description>\s*</category>"
matches = re.findall(pattern, taxonomy_string, re.DOTALL)
for name, description in matches:
taxonomy.append({"name": name.strip(), "description": description.strip()})
return taxonomy
def generate_taxonomy(state: TaxonomyGenerationState):
summaries = [doc["summary"] for doc in state["documents"]]
taxonomy_string = generate_taxonomy_chain.invoke({"summaries": summaries})
return {"candidate_taxonomy": parse_taxonomy(taxonomy_string)}- Prompt: 使用 tnt-llm-generate-taxonomy 提示,指定生成 5 个聚类(可调整)。
- LLM: 使用更强大的 Claude-3.5-Sonnet 模型,以确保分类体系的质量。
- Output Parser: 解析 XML 格式的分类体系,提取类别名称和描述。
- Node: generate_taxonomy 是一个 LangGraph 节点,基于文档摘要生成候选分类体系。
2.5 分类体系优化(Refine Taxonomy)
第三步是优化候选分类体系,合并相似类别,剔除冗余。代码定义了 refine_taxonomy_chain:
refine_prompt = hub.pull("wfh/tnt-llm-refine-taxonomy")
refine_taxonomy_chain = (
refine_prompt
| ChatAnthropic(model="claude-3-5-sonnet-latest")
| StrOutputParser()
).with_config(run_name="RefineTaxonomy")
def refine_taxonomy(state: TaxonomyGenerationState):
candidate_taxonomy = state["candidate_taxonomy"]
taxonomy_string = refine_taxonomy_chain.invoke({"candidate_taxonomy": candidate_taxonomy})
return {"taxonomy": parse_taxonomy(taxonomy_string)}- Prompt: 使用 tnt-llm-refine-taxonomy 提示,指导 LLM 优化分类体系。
- LLM: 继续使用 Claude-3.5-Sonnet,以确保高质量的优化结果。
- Node: refine_taxonomy 是一个 LangGraph 节点,将候选分类体系转换为最终分类体系。
2.6 状态图构建
LangGraph 的核心是 StateGraph,代码将其用于协调上述步骤:
from langgraph.graph import StateGraph, END
workflow = StateGraph(TaxonomyGenerationState)
workflow.add_node("map_step", map_step | reduce_summaries)
workflow.add_node("generate_taxonomy", generate_taxonomy)
workflow.add_node("refine_taxonomy", refine_taxonomy)
workflow.set_entry_point("map_step")
workflow.add_edge("map_step", "generate_taxonomy")
workflow.add_edge("generate_taxonomy", "refine_taxonomy")
workflow.add_edge("refine_taxonomy", END)
graph = workflow.compile()- Nodes: 三个节点分别对应摘要生成(map_step)、候选分类体系生成(generate_taxonomy)、分类体系优化(refine_taxonomy)。
- Edges: 定义了节点间的执行顺序:map_step -> generate_taxonomy -> refine_taxonomy -> END。
- Compilation: workflow.compile() 生成可执行的 LangGraph 图。
2.7 示例运行
代码提供了一个简单的对话日志数据集,并运行工作流:
sample_logs = [
{"id": "1", "content": "User asked about the weather in New York."},
{"id": "2", "content": "User inquired about flight schedules to Paris."},
{"id": "3", "content": "User requested restaurant recommendations in London."},
{"id": "4", "content": "User asked for help with math homework."},
{"id": "5", "content": "User wanted to know the capital of Brazil."}
]
state = {"documents": sample_logs}
result = graph.invoke(state)- Input: 一个包含 5 条对话日志的列表。
- Output: 最终状态包含原始文档、摘要、候选分类体系和优化后的分类体系。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9648