目前最接近 SORA 的开源模型是 Latte,它采用了与 SORA 相同的 Vision Transformer 架构。Vision Transformer 究竟有何独特之处?它与之前的方法有何不同?
Latte 尚未开源其文本转视频训练代码。我们复制了论文中的文本转视频训练代码,并将其提供给任何人使用,以训练他们自己的 SORA 替代模型。我们自己的训练效果如何?详细信息将在下面讨论。
01
从 3D U-Net 到 Vision Transformer
图像生成已经相当成熟,其中UNet模型结构是图像生成最常用的:

2D UNet 架构
U-Net是一种对输入图像先进行压缩缩小,再逐渐解码放大的网络结构,形状像一个U。早期的视频生成模型扩展了U-Net结构来支持视频。
从图像到视频实际上非常简单 – 只需通过添加时间维度将 2D 高度 x 宽度扩展为 3D:

图像转视频,2D转3D
早期的视频生成网络结构只是通过合并时间维度将二维 UNet 扩展为三维 UNet。
通过在这个时间维度内集成一个变换器,模型可以学习图像在给定时间点(例如第 n 帧)应该是什么样子。
最初,给出一个提示,它会生成一张图像。3D UNet 给出一个提示,会生成 16 张图像。
3D UNet 结构的问题在于,Transformer 只能在 UNet 内部发挥作用,无法看到全局。这通常会导致视频中连续帧之间的一致性较差,并且模型对较大的动作和运动也缺乏足够的学习能力。
如果你仍然对 2D-UNet 和 3D-UNet 的网络结构感到困惑,其实并没有那么复杂。网络设计背后并没有那么多逻辑,只要记住深度学习最重要的一点:“只需添加更多层”!
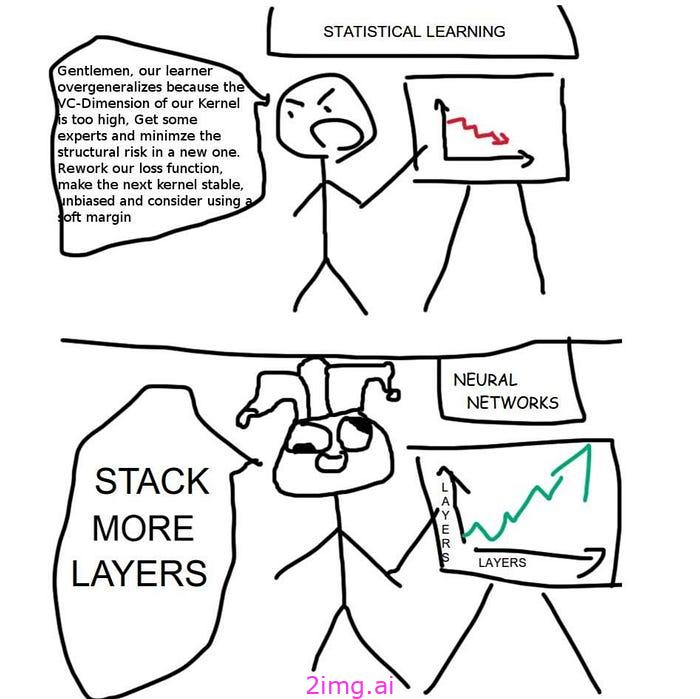
只需添加更多层
02
视觉转换器
3D UNet 中的 Transformer 只在 UNet 内部工作,无法看到全局。而 Vision Transformer 则允许 Transformer 全局主导视频生成。
Vision Transformer 的建模方法更类似于语言模型:我们可以直接将视频看作一个序列,序列中的每一个数据块都可以是一小块图像。
与语言模型标记器的工作方式类似,视频可以被编码成一系列标记。
一旦序列建立起来,我们就可以直接应用Transformers。

视频修补
从数学上讲,Vision Transformer 非常简单;它采用与语言模型类似的机制:将视频转换为标记序列,然后积极应用多层转换器。
这种简单的设计非常符合 OpenAI 的风格——简单而强大。
OpenAI 其实并不喜欢数学复杂度高或者花哨的方法,早期 OpenAI 的 GPT-2 相对于 T5、DeBerta 等各种花哨的模型,有些被人瞧不起,觉得太过简单粗暴。
但相对简单易操作的模型结构其实可以让模型更容易稳定地扩展到更大量的训练数据。OpenAI 选择不竞争模型结构,而是竞争数据。
然后,它就会堆积数 PB 的数据和数以万计的 GPU。
我和 OpenAI 之间的唯一区别只是几万个 GPU。

将 100k 个 GPU 投入到 1000 层的转换器中
与 3D UNet 相比,Vision Transformer 让模型更加专注于学习运动图像的模式。
更大的运动幅度和更长的视频长度一直是视频生成模型所面临的挑战,Vision Transformer 显著增强了这些方面的能力。
03
训练你的开源 SORA 替代品 Latte
Latte 采用了前面提到的视频切片序列和 Vision Transformer 方法。这与大家对 SORA 的普遍理解一致。
Latte 尚未开源文本转视频模型的训练代码,我们已将论文的训练代码复制到此处供大家参考:https://github.com/lyogavin/train_your_own_sora,请大家放心使用。
训练仅需三个步骤:
- 下载并训练模型,安装环境
- 准备培训视频
- 运行训练:
运行
有关更多详细信息,请参阅github repo。
我们还对训练过程做了一些改进:
- 增加了对梯度累积的支持以减少内存需求
- 在训练期间包含验证样本,以帮助验证训练过程
- 增加了对 wandb 的支持
- 包括对无分类器指导训练的支持。
04
模型性能
Latte 的官方视频如下:
官方视频看起来表现良好,特别是在显著动作方面。
我们也在自己的训练数据上对比了各种模型,Latte 确实表现不错,但并不是最好的模型,还有其他开源模型表现更好。
虽然Latte采用了有效的网络结构,但是其规模更大,根据著名的缩放定律,意味着它对训练数据的数量和质量的要求更高。
视频模型的性能很大程度上依赖于其预训练图像模型的性能。看来 Latte 使用的预训练基础图像模型也需要加强。
我们将来会继续分享其他性能更好的模型,所以请务必关注我的博客。
05
硬件要求
由于规模较大,训练 Latte 需要配备 80GB 内存的 A100 或 H100。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/3860