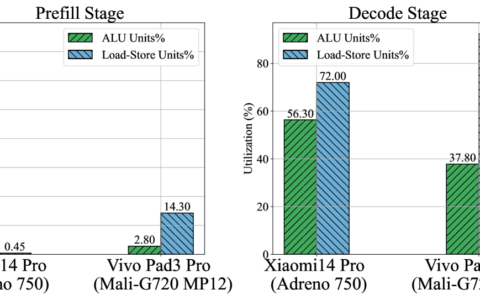
在生产环境中部署 LLM 会带来重大挑战,尤其是在高效服务所需的计算资源方面。如果您以前尝试过,您可能很清楚,服务 LLM 的最关键资源之一是 GPU 内存。这些模型的巨大规模,加上其推理过程的动态性质,需要仔细规划和优化内存使用情况。

准确估计 GPU 内存需求至关重要,原因如下:
- 成本效率: GPU 是昂贵的资源。高估内存需求会导致不必要的硬件支出,而低估则会导致系统故障或性能下降。
- 性能优化:适当的内存管理可确保模型高效运行,为用户提供更快的响应并处理更多的并发请求。
- 可扩展性:随着需求的增长,了解内存需求对于扩展服务变得至关重要,同时又不影响性能或产生过高的成本。
尽管计算 LLM 所需的 GPU 内存非常重要,但计算起来却并不简单。模型大小、序列长度、批处理大小和解码算法等因素会以复杂的方式影响内存消耗。此外,传统的内存分配方法通常会因碎片化和键值 (KV) 缓存等动态内存组件的低效管理而导致大量浪费。
在本文中,我将尽力解释计算用于服务 LLM 的 GPU 内存需求的过程。我将分解影响内存使用量的组件,并逐步指导如何根据模型参数和工作负载特征估算内存占用量。此外,我将探索高级优化技术,例如 Paged Attention 和 vLLM 服务系统,这些技术可以显著减少内存消耗并提高吞吐量。在本文结束时,您将全面了解如何规划和优化 LLM 的 GPU 内存使用量,从而实现在实际应用中高效且经济高效的部署。
在深入研究之前,我鼓励大家阅读这篇优秀的论文:使用 PagedAttention 实现大型语言模型服务的有效内存管理,它提供了详细的观点和强大的技术理解。我还想指出,我目前对估算 GPU 内存需求的大部分理解和方法都来自这个来源。我们将在本文后面探讨的其他参考资料也有助于形成这些见解。
剩余内容需解锁后查看
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6305