LATS(LLM Agent Tree Search) 展示了一种结合 大型语言模型(LLM) 和 树搜索(Tree Search) 的 AI Agent 开发范式,用于解决需要复杂推理和探索的问题。LATS 通过将 LLM 的生成能力与树搜索的系统性探索结合,模拟人类在决策过程中的试错和优化行为。它特别适用于需要多步推理、假设验证或优化的问题,例如数学推理、规划任务或代码调试。
从 AI Agent 开发范式 的角度,LATS 代表了一种 探索式推理(Exploratory Reasoning) 和 结构化决策(Structured Decision-Making) 的结合,突破了传统 LLM 单次生成或线性链式调用的局限。它体现了现代 AI Agent 开发中以下趋势:
- 从单一预测到系统性探索:通过树搜索探索多种可能路径,而非依赖单次 LLM 输出。
- 状态驱动的动态交互:利用 LangGraph 的状态管理支持多轮、上下文感知的决策。
- 工具增强的智能体:结合外部工具(如计算器、搜索)提升推理能力。
- 可控性和可解释性:通过图结构和状态追踪提供更高的透明度和调试能力。
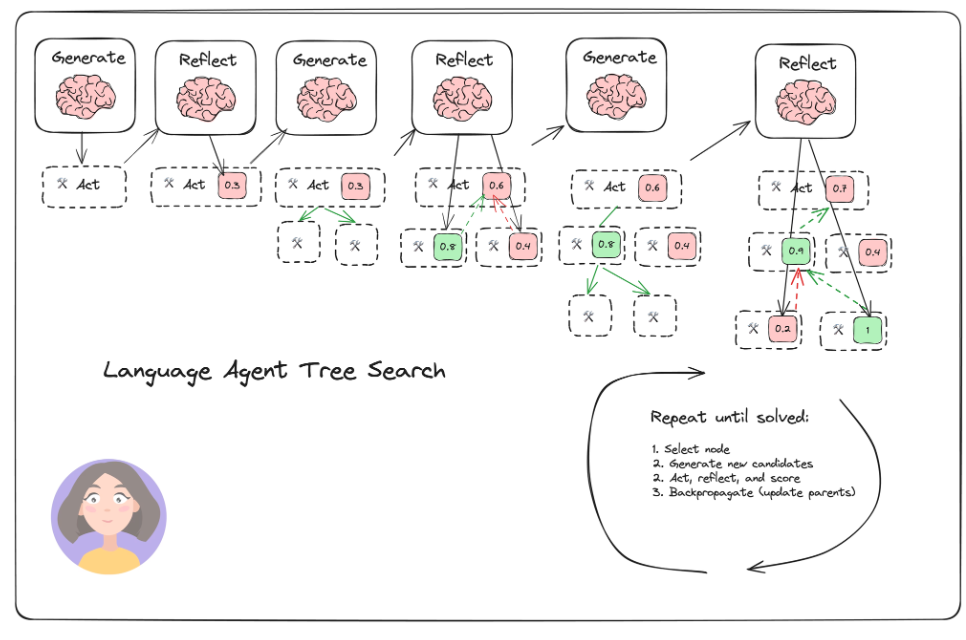
具体来看,LATS 基于(贪婪的)蒙特卡洛树搜索。对于每个搜索步骤,它会选择“置信上限”最高的节点,该指标用于平衡开发利用(最高平均奖励)和探索(最低访问次数)。从该节点开始,它会生成 N(在本例中为 5)个新的候选操作,并将它们添加到树中。当它生成有效解决方案或达到最大滚动次数(搜索树深度)时,它会停止搜索。
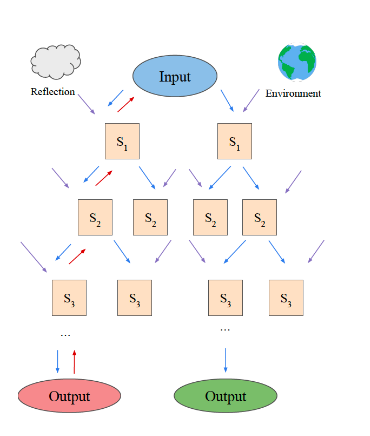
LATS 示例为现代 AI Agent 开发提供了以下关键启示,反映了从传统 LLM 到复杂智能体的范式转变:
- 从单次生成到探索式推理:
- 传统 LLM 依赖单次预测,容易陷入局部最优。LATS 通过树搜索引入系统性探索,模拟人类的多步推理过程。
- AI Agent 开发应注重解空间的全面探索,结合搜索算法(如蒙特卡洛树搜索)提升推理能力。
- 结构化与模块化的重要性:
- LATS 将生成、评估和扩展分解为独立节点,通过图结构实现清晰的逻辑分离。
- 模块化设计是复杂 AI Agent 的核心,开发者应将任务分解为可复用的组件,提升可维护性和扩展性。
- 工具增强的必要性:
- LATS 集成工具(如计算器)弥补 LLM 的局限,显著提升推理的准确性。
- 启示:AI Agent 应与外部工具深度集成,利用专业化工具处理 LLM 无法高效完成的子任务(如计算、搜索、数据验证)。
- 状态驱动的动态交互:
- LangGraph 的状态管理支持动态调整搜索路径,适应问题变化。
- 状态管理是 AI Agent 的核心,开发者需设计持久化上下文以支持多轮交互和动态决策。
- 可控性与可解释性的平衡:
- LATS 通过图结构和 LangSmith 提供高度可控性和透明度,开发者可以追踪每一步决策。
- 生产级 AI Agent 需要平衡复杂功能与可解释性,集成调试工具(如 LangSmith)以优化性能和用户信任。
- 计算成本与效率的权衡:
- LATS 的高计算成本突显了树搜索在效率上的挑战。
- 开发者需在推理能力与资源消耗间找到平衡,探索高效搜索策略(如启发式剪枝、并行搜索)。

数据结构定义
LATS 的工作流需要维护一个复杂的状态对象(相对与其余的范式,确实2倍左右的复杂),用于管理搜索树和迭代过程。代码定义了以下关键数据结构:
from typing import TypedDict, List, Dict, Optional
from dataclasses import dataclass
import chess
@dataclass
class TreeNode:
state: chess.Board 当前棋盘状态(chess.Board 对象)。
action: Optional[str] = None 导致该节点的行动(如棋步,UCI 格式,例如 "e2e4")
parent: Optional["TreeNode"] = None 父节点引用
children: List["TreeNode"] = None 子节点列表
visits: int = 0 节点被访问的次数
value: float = 0.0 节点的累积评估价值
depth: int = 0 节点在搜索树中的深度
class LATSState(TypedDict):
input: str 用户输入的初始任务(如棋盘的 FEN 字符串)
board: chess.Board 当前棋盘状态
tree: Dict[str, TreeNode] 搜索树的节点字典,键为棋盘的 FEN 字符串,值为 TreeNode
root: TreeNode 搜索树的根节点
current_node: TreeNode 当前处理的节点
max_depth: int 搜索的最大深度(如 3
max_iterations: int 最大迭代次数(如 10
iteration: int 当前迭代次数
final_answer: Optional[str] 最终答案(如最佳棋步)2.3 核心组件与工作流
LATS 的实现分为多个节点,每个节点负责搜索树的一个阶段。以下是主要节点的分析,基于代码上下文和 MCTS 标准实现。
2.3.1 初始化(Initialize)
第一步是初始化搜索树和状态:
def initialize(state: LATSState):
board = chess.Board(state["input"])
root = TreeNode(state=board, depth=0)
tree = {board.fen(): root}
return {
"board": board,
"tree": tree,
"root": root,
"current_node": root,
"max_depth": state.get("max_depth", 3),
"max_iterations": state.get("max_iterations", 10),
"iteration": 0,
"final_answer": None
}- 逻辑:
- 基于输入的 FEN 字符串创建棋盘(chess.Board)。
- 初始化根节点(TreeNode),并将其添加到树中(以 FEN 为键)。
- 设置默认的 max_depth(3)和 max_iterations(10)。
- 节点:initialize 设置初始状态,为后续搜索做准备。
- 特点:使用 python-chess 确保棋盘状态的准确性。
2.3.2 节点选择(Select Node)
第二步是选择要扩展的节点,使用 UCB 公式:
import math
def ucb_score(node: TreeNode, parent_visits: int, c: float = 1.4) -> float:
if node.visits == 0:
return float("inf")
return node.value / node.visits + c * math.sqrt(math.log(parent_visits) / node.visits)
def select_node(state: LATSState):
current = state["current_node"]
if current.depth >= state["max_depth"] or not current.state.legal_moves:
return state
if not current.children:
return {"current_node": current}
parent_visits = current.visits or 1
best_score = -float("inf")
best_child = None
for child in current.children:
score = ucb_score(child, parent_visits)
if score > best_score:
best_score = score
best_child = child
return {"current_node": best_child}
- 逻辑:
- 如果当前节点达到最大深度或无合法走法,返回当前状态。
- 如果当前节点无子节点,选择其进行扩展。
- 否则,计算每个子节点的 UCB 分数,选择分数最高的子节点。
2.3.3 节点扩展(Expand Node)
第三步是扩展选中的节点,生成子节点:
def expand_node(state: LATSState):
current = state["current_node"]
if current.children or not current.state.legal_moves:
return state
legal_moves = [move.uci() for move in current.state.legal_moves]
tree = state["tree"]
children = []
for move in legal_moves:
board = current.state.copy()
board.push_uci(move)
child = TreeNode(
state=board,
action=move,
parent=current,
depth=current.depth + 1
)
tree[board.fen()] = child
children.append(child)
current.children = children
return {"tree": tree, "current_node": children[0] if children else current}- 逻辑:
- 如果节点已有子节点或无合法走法,返回当前状态。
- 使用 python-chess 生成所有合法走法(UCI 格式)。
- 为每个走法创建子节点,复制当前棋盘并应用走法,更新树结构。
- 选择第一个子节点作为新的 current_node(用于后续评估)。
- 节点:更新 tree 和 current_node,扩展搜索树。
- 特点:依赖 python-chess 确保走法准确,避免 LLM 在生成走法时的潜在错误。
2.3.4 节点评估(Evaluate Node)
第四步是评估子节点的价值:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
llm = ChatOpenAI(model="gpt-4o", temperature=0.7)
evaluate_prompt = ChatPromptTemplate.from_template(
"""Given the chess board state (FEN: {fen}),
evaluate the position from the perspective of the current player.
Provide a score between -1 (very bad) and 1 (very good).
Output format:
```json
{"value": 0.5}
"""
)
evaluate_chain = evaluate_prompt | llm | JsonOutputParser()
def evaluate_node(state: LATSState):
current = state["current_node"]
fen = current.state.fen()
result = evaluate_chain.invoke({"fen": fen})
value = result["value"]
current.visits += 1
current.value += value
return {"current_node": current}2.3.5 回溯(Backpropagate)
第五步是将评估价值向上传播:
def backpropagate(state: LATSState):
current = state["current_node"]
value = current.value / max(current.visits, 1)
while current.parent:
current = current.parent
current.visits += 1
current.value += value
return {"current_node": state["root"], "iteration": state["iteration"] + 1}
- 逻辑:
- 计算当前节点的平均价值(value / visits)。
- 将价值和访问次数传播到所有父节点,直到根节点。
- 将 current_node 重置为根节点,增加迭代计数。
- 节点:更新树中节点的统计信息,准备下一次迭代。
2.3.6 答案生成(Generate Answer)
最后一步是生成最终答案:
def generate_answer(state: LATSState):
if state["iteration"] < state["max_iterations"]:
return state
root = state["root"]
if not root.children:
return {"final_answer": "No legal moves available"}
best_child = max(root.children, key=lambda c: c.visits)
return {"final_answer": best_child.action}- 逻辑:
- 如果未达到最大迭代次数,继续搜索。
- 否则,从根节点的子节点中选择访问次数最多的节点(最优行动)。
- 返回最佳行动(如棋步)。
- 节点:设置 final_answer 为最佳棋步。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9629