LLMCompiler 是一种代理架构,旨在通过(有向无环图) DAG 中的即时执行任务来加速代理任务的执行。它还通过减少对 LLM 的调用次数来节省冗余 token 的使用成本。
它包含三个主要组件:
- 规划器(Planner):以 DAG 形式传输任务。
- 任务获取单元(Plan and Schedule):调度任务,并在任务可执行后立即执行。
- 连接器(Joiner) :响应用户或触发第二个计划。
以下是其计算图的概述:
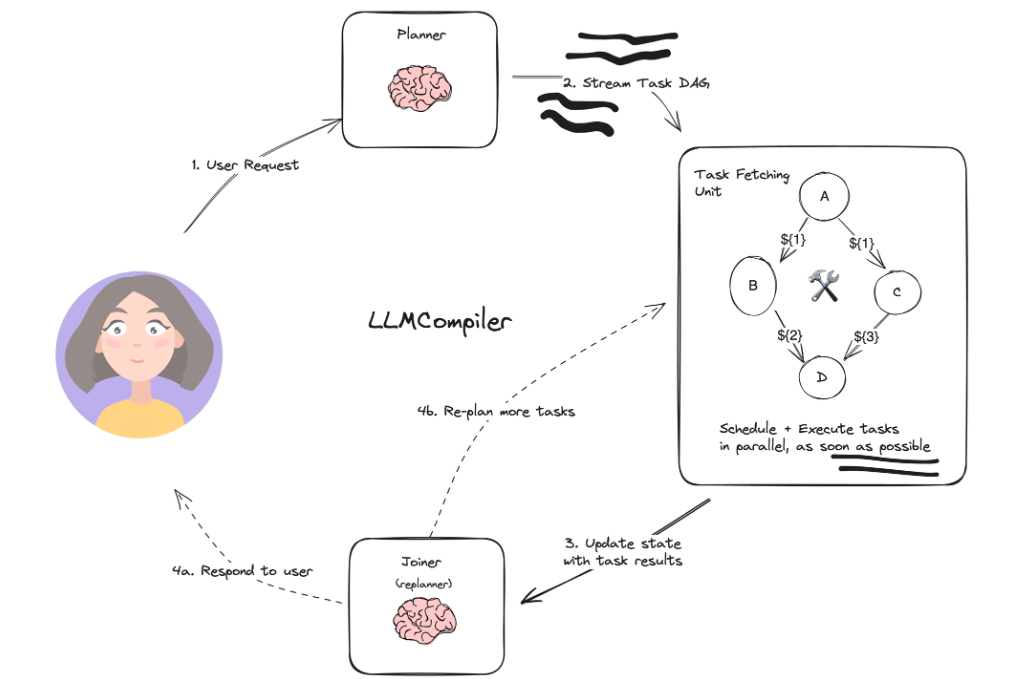
LLCompiler(Large Language Model Compiler) 展示了一种将复杂任务分解为可执行计划的 AI Agent 开发范式。LLCompiler 借鉴了编译器的设计理念,将用户的高级指令(类似“源代码”)分解为一系列低级操作(类似“机器码”),并通过 LangGraph 的图结构动态执行这些操作。LLCompiler 特别适用于需要任务规划、动态调度和多步骤执行的场景,例如自动化工作流、复杂查询处理或多工具协作。
LLCompiler 代表了一种 任务分解与动态执行 的范式,突破了传统 LLM 单次生成或静态链式调用的局限。它体现了现代 AI Agent 开发中以下趋势:
- 从单步推理到任务规划:通过规划和分解,将复杂任务转化为可执行的步骤序列。
- 动态调度与并行执行:利用图结构支持条件分支和并行任务,提升效率。
- 工具增强的智能体:结合外部工具(如 API、数据库)实现复杂功能。
- 可控性与可扩展性:通过模块化设计和状态管理提供更高的透明度和灵活性。
任务获取单元: { tool:BaseTool, dependencies:number[],} 基本思路是,一旦满足依赖关系,就开始执行工具。这是通过多线程实现的。我们将在下面结合任务获取单元和执行器。
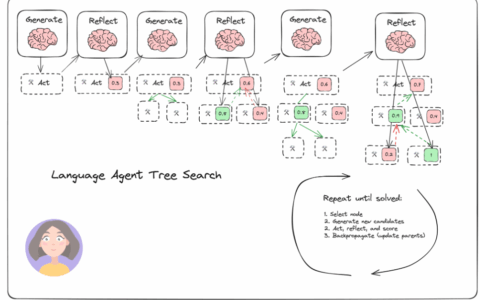
这张图较好的展示了各个主要模块间的内容。
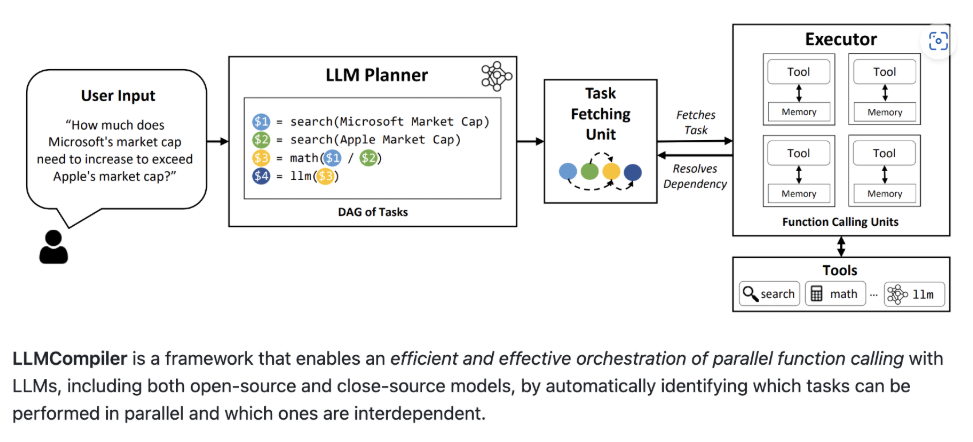
核心节点主要有这几个,
- Planner Node:根据用户输入生成任务计划(Task Plan),分解为一系列操作。
- Scheduler Node:管理任务的执行顺序,决定哪些操作可以并行或按序执行。
- Executor Node:执行具体操作(如调用工具、生成响应)。
- Joiner Node:聚合并行任务的结果,更新状态。
核心组件与工作流
LLM Compiler 的实现分为多个节点,每个节点负责工作流的一个阶段。以下是主要节点的分析:
2.3.1 计划生成(Plan Generation)
第一步是使用 LLM 生成结构化的执行计划。代码定义了一个 plan 节点:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
llm = ChatOpenAI(model="gpt-4o", temperature=0)
plan_prompt = ChatPromptTemplate.from_template(
"""Given the following user input, generate a structured execution plan as a JSON object.
The plan should break down the task into steps, specifying:
- step_id: Unique identifier for the step
- description: Brief description of the step
- tool: Tool to be used (e.g., 'search', 'calculate', 'llm')
- dependencies: List of step_ids that must be completed before this step
Input: {input}
Output format:
```json
[
{"step_id": "1", "description": "...", "tool": "...", "dependencies": [...]},
...
]
"""
)
plan_chain = plan_prompt | llm | JsonOutputParser()
def plan(state: LLMCompilerState):
input_query = state["input"]
plan = plan_chain.invoke({"input": input_query})
return {"plan": plan, "tasks": plan}2.3.2 任务调度(Task Scheduler)
第二步是动态调度任务,决定哪些任务可以执行。代码定义了一个 `scheduler` 节点:
def scheduler(state: LLMCompilerState):
tasks = state["tasks"]
task_results = state["task_results"]
ready_tasks = []
remaining_tasks = []
for task in tasks:
dependencies_met = all(dep in task_results for dep in task.get("dependencies", []))
if dependencies_met and task["step_id"] not in task_results:
ready_tasks.append(task)
else:
remaining_tasks.append(task)
return {"tasks": remaining_tasks, "ready_tasks": ready_tasks}- Logic: 检查每个任务的依赖是否已满足(即依赖的任务结果存在于 task_results)。
- Output: 将任务分为 ready_tasks(可立即执行)和 remaining_tasks(等待依赖)。
- Node: scheduler 是一个纯逻辑节点,更新状态以支持动态调度。
2.3.3 任务执行(Task Execution)
第三步是执行可运行的任务。代码定义了一个 execute_task 节点,并集成了工具:
from langchain_community.tools import TavilySearchResults
search_tool = TavilySearchResults(max_results=3)
tools = {
"search": search_tool,
"calculate": lambda x: str(eval(x)),
"llm": llm
}
def execute_task(state: LLMCompilerState):
ready_tasks = state.get("ready_tasks", [])
task_results = state["task_results"].copy()
for task in ready_tasks:
tool_name = task["tool"]
description = task["description"]
step_id = task["step_id"]
if tool_name in tools:
if tool_name == "llm":
result = tools[tool_name].invoke(description)
task_results[step_id] = result.content
else:
result = tools[tool_name].invoke(description)
task_results[step_id] = str(result)
else:
task_results[step_id] = f"Tool {tool_name} not found"
return {"task_results": task_results}- Tools:
- search: 使用 Tavily 搜索工具,获取外部信息。
- calculate: 简单计算工具,通过 eval 执行数学表达式。
- llm: 直接调用 GPT-4o 处理推理任务。
- Logic: 遍历 ready_tasks,根据任务的 tool 字段调用对应工具,存储结果到 task_results。
- Node: execute_task 执行任务并更新状态。
2.3.4 结果聚合(Joiner)
第四步是检查任务完成情况并生成最终答案。代码定义了一个 joiner 节点:
joiner_prompt = ChatPromptTemplate.from_template(
"""Given the user input and the results of the executed tasks,
provide a final answer to the user's query.
Input: {input}
Task Results: {task_results}
Output format:
```json
{"final_answer": "..."}
"""
)
joiner_chain = joiner_prompt | llm | JsonOutputParser()
def joiner(state: LLMCompilerState):
if state["tasks"]: # If there are remaining tasks
return {"final_answer": None}
input_query = state["input"]
task_results = state["task_results"]
result = joiner_chain.invoke({"input": input_query, "task_results": task_results})
return {"final_answer": result["final_answer"]}2.3.5 路由逻辑(Router)
代码定义了一个 `router` 函数,用于动态路由到下一个节点:
def router(state: LLMCompilerState):
if state["final_answer"] is not None:
return "end"
if state.get("ready_tasks"):
return "execute_task"
return "scheduler"
- Logic:
- 如果 final_answer 已生成,路由到 END。
- 如果有 ready_tasks,路由到 execute_task。
- 否则,路由到 scheduler 检查任务状态。
- Role: router 实现动态调度,确保任务按依赖顺序执行。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/9635