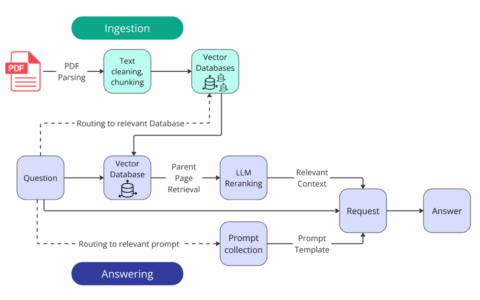
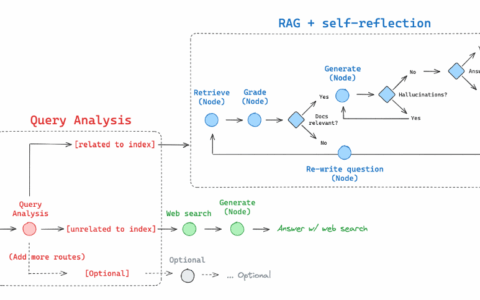
自动检索和汇总大量文本信息有许多有用的应用。其中最成熟的应用之一是检索增强生成 (RAG),它涉及从大型语料库中提取相关文本块(通常通过语义搜索或其他过滤步骤)以回答用户问题。然后,法学硕士对这些文本块进行解释或总结,以提供高质量、准确的答案。为了使提取的文本块尽可能与问题相关,它们在语义上连贯是非常有帮助的,这意味着每个文本块都“关于”一个特定概念,并且本身就包含有用的信息包。
分块的应用范围不仅限于 RAG。假设我们有一份复杂的文档,比如一本书或一篇期刊文章,我们想快速了解其中包含的关键概念。如果可以将文本聚类为语义连贯的组,然后以某种方式总结每个聚类,那么这确实有助于加快洞察速度。出色的软件包BertTopic(请参阅本文以获得很好的概述)可以在这里提供帮助。
无论是作为最终产品还是在开发过程中,对区块进行可视化也可以提供深刻见解。人类是视觉学习者,因为我们的大脑从图形和图像中收集信息的速度比从文本流中收集信息的速度要快得多。根据我的经验,如果不以某种方式将区块可视化或全部阅读,就很难理解分块算法对文本做了什么以及最佳参数可能是什么,而这在大型文档的情况下是不切实际的。
在本文中,我们将探索一种将文本拆分为语义上有意义的块的方法,重点是使用图形和图表来了解正在发生的事情。在此过程中,我们将涉及嵌入向量的降维和层次聚类,以及使用 LLM 来总结块,以便我们能够快速查看存在的信息。我希望这可以为任何研究语义分块作为其应用程序中的潜在工具的人提供更多的想法。我将在这里使用 Python 3.9、LangChain 和 Seaborn,详细信息请参阅repo。
1.什么是语义分块?
有几种标准的分块类型,要了解更多,我推荐这个优秀的教程,它也为本文提供了灵感。假设我们处理的是英文文本,最简单的分块形式是基于字符的,我们选择一个固定的字符窗口,然后将文本简单地分成该长度的块。我们可以选择在块之间添加重叠,以保留它们之间顺序关系的一些指示。这在计算上很简单,但不能保证块在语义上有意义,甚至是完整的句子。
递归分块通常更有用,被视为许多应用程序的首选算法。该过程采用分层分隔符列表(LangChain 中的默认值为[“\n\n”, “\n”, “ ”, “”])和目标长度。然后,它以递归方式使用分隔符拆分文本,沿列表向下推进,直到每个块小于或等于目标长度。这在保留完整段落和句子方面要好得多,这很好,因为它使块更有可能连贯。但是它没有考虑语义:如果一个句子紧接着最后一个句子,并且恰好位于块窗口的末尾,则句子将被分开。
在语义分块中, LangChain和LlamaIndex中都有实现,拆分是基于连续块嵌入之间的余弦距离进行的。因此,我们首先将文本分成小而连贯的组,可能使用递归分块器。
接下来,我们使用经过训练以生成有意义的嵌入的模型对每个块进行矢量化。通常,这采用基于转换器的双编码器的形式(有关详细信息和示例,请参阅SentenceTransformers库),或像 OpenAI 的端点这样的端点text-embeddings-3-small,这就是我们在这里使用的。最后,我们查看后续块的嵌入之间的余弦距离,并选择距离较大的断点。理想情况下,这有助于创建既连贯又语义不同的文本组。
最近的扩展称为语义双块合并(详情请参阅本文),它尝试通过第二遍和使用一些重新分组逻辑来扩展此方法。例如,如果第一遍在块 1 和 2 之间设置了一个中断,但块 1 和 3 非常相似,它将创建一个包含块 1、2 和 3 的新组。如果块 2 是数学公式或代码块,这将非常有用。
然而,当涉及任何类型的语义分块时,仍然存在一些关键问题:在我们设置断点之前,块嵌入之间的距离可以有多大,这些块实际上代表什么?我们关心这个吗?这些问题的答案取决于应用程序和所讨论的文本。
Paragoger衍生者AI训练营。发布者:稻草人,转载请注明出处:https://www.shxcj.com/archives/6348